中文内容

概览
- Vega 允许用户证明政府签发凭证中的事实(如年龄、个人身份、职业状态等),而无需透露凭证本身。该凭证始终保留在设备中,不会离开。
- 在常规客户端设备上,零知识证明的生成时间不到 100 毫秒,且无需进行可信设置,从而使大规模隐私身份验证具备实际应用的可行性。
- “折叠与复用”证明机制意味着,在向不同服务或通过 AI 代理进行重复验证时,首次证明完成后即可跳过大部分高开销计算工作。
- Vega 支持移动驾照和欧盟数字身份钱包等现实应用格式,采用 Rust 语言构建,并即将开源。
人工智能正在改变人们与数字服务的交互方式,从AI驱动的助手到代表用户行事的自主智能体。随着这些能力的不断提升,强数字身份的价值也日益凸显:用户需要可靠的方式来建立信任,无论是证明自己是真人,还是与AI中介服务共享凭证。政府签发的凭证仍然是信任的最强基石,但如今的验证方法通常要求人们直接交出凭证。随着AI智能体开始代表人类行事并与去中心化系统交互,对快速且保护隐私的凭证验证方式的需求只会不断增长。
这些需求已在政策层面逐步落地。各国政府正迅速推进数字身份的规范化。欧盟数字身份(EUDI)框架旨在为所有欧盟公民提供数字钱包,而欧盟的年龄验证蓝图和英国《在线安全法》等举措则强制要求采用基于政府身份信息的年龄核验方法。应用提供商面临两难困境:他们要么采用基于AI的年龄估算等精度较低的方法,要么要求用户上传身份证件,从而牺牲用户隐私。
凭证被上传、处理,有时被存储,最终(希望如此)被删除。然而,备受瞩目的数据泄露事件已多次曝光用户为日常验证而共享的政府身份证件。这些绝非边缘案例。它们是可预见的必然结果:现有系统要求用户交出最敏感的文件,却仅仅是为了证明一项简单的信息。
这正是我们希望通过 Vega 解决的问题:能否在不暴露凭证本身的情况下,实现高效实用的凭证信息证明?
迈向 Vega 之路:从理念到实践
零知识证明(ZKPs)正是实现这一目标的密码学工具。其原理很简单:它允许用户证明某项声明(例如“我已年满21岁”),而无需透露任何其他信息。在实际应用中,这意味着用户可以在验证方完全看不到驾驶证的情况下,向网站、应用程序或由AI代理介导的服务证明自己的年龄。该证明直接作用于签发的原始凭证,因此签发方无需进行任何更改。
这并非一个新概念。真正的挑战一直在于其实用性。以往的密码学系统要么需要可信设置,且每当逻辑变更时就必须重新执行;要么为了避免可信设置而牺牲性能,在此过程中往往生成体积庞大的证明。对于实际应用而言,证明的生成速度必须足够快、体积必须足够小以便于快速传输,且运行效率必须足以在移动设备上流畅执行。
多年来,我们一直致力于打造一套切实可行的解决方案。隐私保护身份验证始终是贯穿始终的关键应用场景(在新标签页中打开),而 Vega 的证明系统正是借鉴了该研究方向中的多项基础模块:
- Spartan(在新标签页中打开)展示了如何高效证明 R1CS(一种用于通用证明系统的标准陈述表达方式),该方法无需可信设置即可生成简洁的证明。
- Nova(在新标签页中打开)引入了折叠方案,该方案允许证明者将多个计算实例压缩为单个实例。
- HyperNova(在新标签页中打开)表明,Nova 的折叠技术也为零知识提供了关键构建模块:将真实实例与随机实例进行折叠可以隐藏底层秘密数据,该技术被称为“NovaBlindFold”。
- NeutronNova(在新标签页中打开)提供了最高效的折叠方案,可一次性批量处理实例。
Vega 将这些构建模块整合至单一的证明系统中。其核心设计目标是简洁性。Spartan、Nova 和 NeutronNova 以直接的方式组合而成,电路仅由少量标准组件构建,无需复杂的多域构造,也无需可信设置。基于这一简洁的基础,Vega 增加了在同一凭证的多个证明之间复用工作的能力,以及一种以极低开销实现零知识的新方法。由此得到的系统易于审计、可轻松扩展至新的凭证格式,且便于部署。
性能
在通用客户端设备上,Vega 仅需 92 毫秒(ms)即可从典型的约 2 千字节(KB)大小的移动驾照中生成年龄零知识证明。生成的证明大小为 108 KB,验证仅需 23 毫秒。该过程无需可信设置。证明者密钥大小为 464 KB,可轻松存入任何手机。对于更小的凭证,证明生成时间降至 62 毫秒,证明大小为 83 KB,验证时间为 17 毫秒。在实际使用中,用户只需点击按钮出示凭证,92 毫秒后证明即可生成。服务端仅能获知所请求的特定事实;凭证本身始终不会离开手机。
底层原理:折叠、复用与查找
Vega 的速度源于两个核心理念:折叠与复用证明,以及以查找为中心的电路设计。下图展示了端到端的完整证明流程。
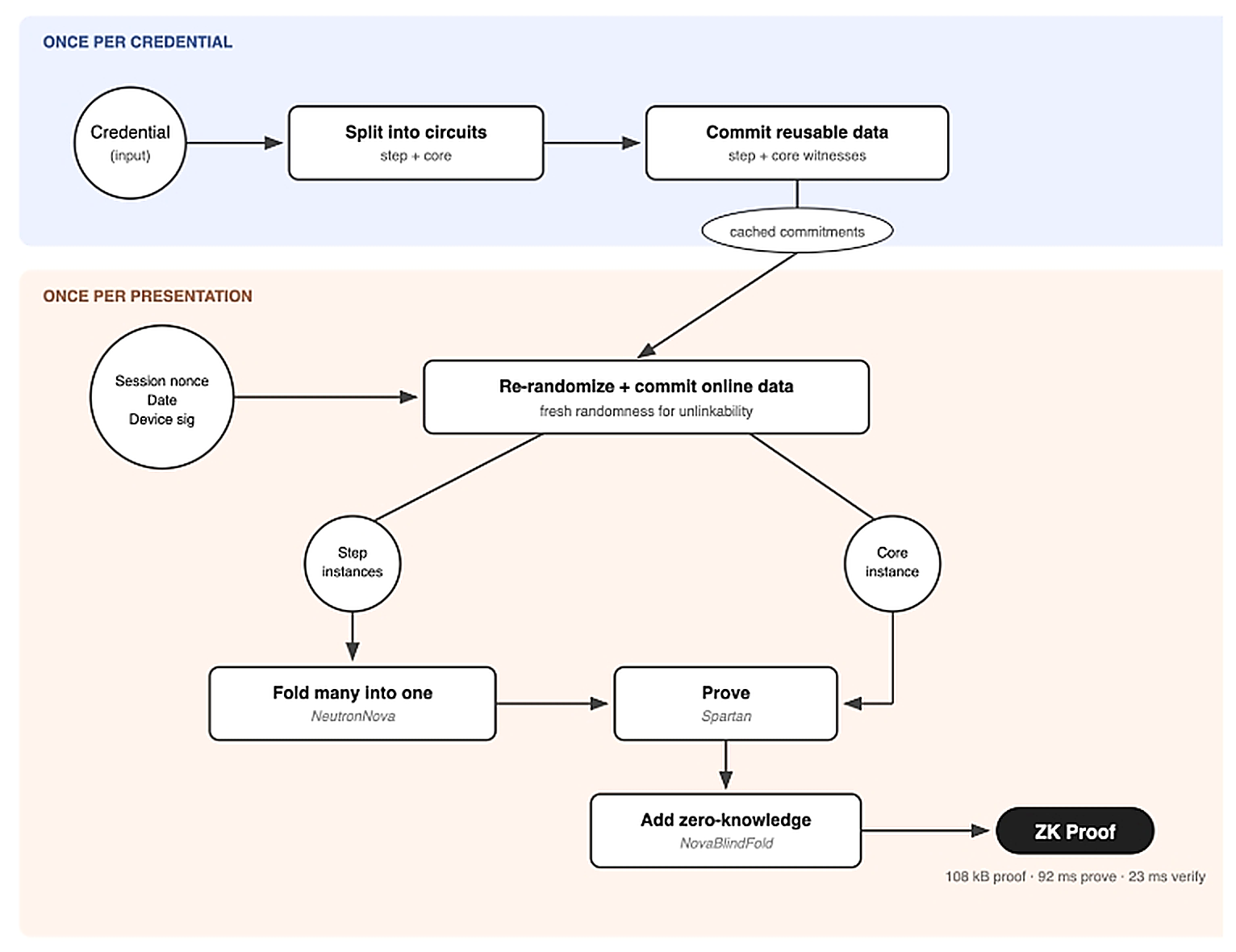
哈希难题,以及折叠技术如何解决它
凭证证明必须完成两项计算成本高昂的操作:使用 SHA-256 对凭证字节进行哈希运算,以及验证签发方的数字签名。签名验证通常是性能瓶颈,但 Vega 通过在签名算术原生的域中进行运算,规避了该开销。因此,哈希运算成为了主要成本。SHA-256 的工作原理是每次对一个 64 字节的块应用相同的压缩函数。直接的电路实现会简单展开所有迭代,导致电路规模随凭证长度增加。对于典型的移动驾照而言,这相当于 30 个压缩块,全部被纳入单个电路中。
我们采用了不同的方法。我们不再对整个哈希进行展开,而是定义一个小型的“步骤”电路来证明单次 SHA-256 压缩步骤,并为每个区块实例化一次。由于这些步骤实例结构完全相同,我们可以利用 NeutronNova 的折叠方案将它们折叠为单个实例。证明者确实需要执行计算来将 30 个步骤实例折叠为一个,但该折叠开销相对较小。随后,Spartan 只需证明一个单步大小的电路,并配合一个独立的“核心”电路来处理其余检查(包括签名验证和年龄谓词),而无需使用包含 30 个展开区块的单体电路。证明密钥仅需描述一个步骤和一个核心,因此无论凭证长度如何,其体积都能保持较小。
此处存在一个需要解决的微妙隐私问题。凭证的长度各不相同,若电路规模随凭证长度而变化,便会泄露信息。为防止这一点,所有步骤电路共享一个已承诺的中间摘要表。核心电路通过私有索引选取相应的摘要。如果证明者选错了条目,发行方的签名验证将失败。
低成本实现零知识
证明系统必须具备零知识特性:验证者除了所证明的声明外,不应获取任何额外信息。现有的实现方案通常在工程实现上较为复杂,且会显著增加证明者的开销。我们找到了一种更简洁的方法。
标准的第一步是,使用隐藏型密码学承诺对证明者发送的每条消息进行承诺,使验证者只能看到承诺值而非实际数据。更具挑战性的问题在于,如何证明这些隐藏的值本应通过验证者的检查。由于验证者仅执行对数级数量的操作,我们将这些检查表示为一个小型约束系统,仅包含数百个约束。随后,我们借助 Nova 的折叠方案将该约束系统与一个随机实例进行折叠。这一步骤隐藏了底层数据,使得零知识的开销仅与该小型约束系统成比例,而非与完整的秘密数据挂钩。
证明一次,多次出示
用户向某个网站出示凭证后,通常还会向其他网站继续出示。在 AI 智能体代表用户处理大量此类交互的场景中,同一凭证每天可能需要出示数十次。在这些出示过程中,凭证本身并不会改变。发生变化的是会话随机数(nonce,由验证方生成的新鲜随机值),以及可能的日期或谓词阈值。
Vega 利用这一结构,将证明方的秘密数据拆分为三部分。共享数据(SHA-256 查找表)与预提交部分(如签发方签名和字段位置)在凭证首次加载时仅计算并提交一次。在线部分(如设备签名和当日日期)则每次都会重新提交。在生成每次证明前,预先计算的承诺会注入新的随机数进行刷新。这种方式比重新计算成本更低,且能确保针对同一凭证生成的两个证明之间无法建立关联。
避免使用解析器
Vega 高效性的另一大关键在于其处理凭证格式的方式。移动驾照采用简明二进制对象表示法(CBOR)进行编码,若将完整的 CBOR 解析器设计为电路,不仅复杂而且成本高昂。但我们意识到,实际上根本不需要解析器。凭证的字节数据已由受信任的签发方签名,因此我们可以确信其格式是规范的。我们只需直接定位并提取所需的具体字段即可。
我们将凭证视为一个字节可寻址的查找表。证明方指出“设备公钥起始于第 847 字节”,并提供相应的字节数据。电路将验证三项内容:提供的字节是否与实际认证的凭证完全匹配;字段开头是否包含正确的 CBOR 前缀,以防证明方错指字段;以及提供的地址是否连续,以防证明方从无关位置拼接字节。该方案仅通过少量查找操作便替代了完整的解析器。
正如上文所述,相同的查找机制也驱动了隐藏长度的哈希运算:电路会构建所有中间 SHA-256 摘要的表,并在真实消息结束的位置选取对应的正确摘要。
设备绑定
零知识凭证证明只有在与凭证持有人绑定时才具有实际效用。若缺乏设备绑定,任何获取了泄露凭证的人都能为任意会话生成有效证明。在 AI 智能体普及的时代,这一点尤为关键:如果智能体能够代表用户出示证明,我们需要密码学层面的保障,以确保该证明确实源自用户本人的设备,而非攻击者或未经授权的智能体。
Vega 通过要求持有者的设备使用设备私钥对全新的会话 nonce 进行签名来解决此问题,该私钥已绑定至手机的安全元件。电路通过查找操作从凭证中提取设备公钥,并验证设备针对该会话 nonce 哈希值的签名。由于设备私钥永远不会离开安全硬件,仅持有已签名的凭证并不足以生成有效的证明。
未来展望
Vega 采用 Rust 语言编写,并即将开源。为 Vega 提供支持的证明系统已作为开源项目 spartan2(在新标签页中打开)发布在 GitHub 上。该论文系与 Darya Kaviani 合作完成,将在即将于旧金山举行的 IEEE 安全与隐私研讨会上发表。
尽管我们以移动驾照作为具体且适时的应用案例,尤其是在欧盟数字身份钱包等新兴框架兴起的背景下,但该证明系统与电路技术具有通用性。它们适用于任何采用稳定字节编码并包含数字签名的凭证格式。
我们认为在以下几个方向中,同一基础原语的重要性将日益凸显。
代表人类携带身份的代理。随着自主 AI 代理开始代表人类行事,无论是预订差旅、与各类服务交互还是签订协议,这些代理都需要证明其所代表人类的相关事实。例如,“我的委托人年满 18 岁”或“我的委托人是持证医师”。代理应当能够携带这些证明,而无需实际持有底层凭证。在人类设备上生成、并通过设备绑定机制与代理会话相绑定的零知识证明,可让代理在不掌握任何秘密的前提下对外出示身份信号。
将链下身份桥接至链上系统。去中心化系统日益需要现实世界的身份信号,例如 KYC 合规、合格投资者身份认证以及司法管辖区核查。目前,该流程通常通过将文件上传至中心化中介来处理,再由中介签发链上证明。用户在此过程中会两次丧失隐私:一次是向中介披露,另一次是在链上暴露,因为该证明在不同交互中可能被关联。基于链下凭证的零知识证明(ZKP)可直接实现桥接:用户证明其政府签发凭证中的某项事实,链上验证者仅接收证明本身。全程无中介接触原始凭证,且重随机化机制确保了重复生成的证明之间无法相互关联。
随着数字身份监管要求的不断扩展,以及 AI 重塑人类与智能体建立信任的方式,对隐私保护型凭证验证的需求将持续增长。我们将 Vega 视为更广泛转变中的一步:从一个证明自身事实就必须让渡身份的世界,迈向一个借助密码学技术让你得以保全身份的世界。
Opens in a new tab



