中文内容


公告
- 新发布 Claude Sonnet 4.6 2026 年 2 月 17 日 Sonnet 4.6 在编码、智能体和大规模专业工作方面提供前沿性能。它可以将持续数天的编码项目压缩到数小时内,并交付可用于生产的解决方案。阅读更多
- Claude Sonnet 4.5 2025 年 9 月 29 日 Sonnet 4.5 是全球最适用于智能体、编码和计算机使用的模型。它也是我们在长时间运行任务方面最准确、最细致的模型,并在编码、金融和网络安全领域具备增强的专业知识。阅读更多
- Claude Sonnet 4 2025 年 5 月 22 日 Sonnet 4 在多个方面较 Sonnet 3.7 有所改进,尤其是编码能力。它提供适用于大多数 AI 使用场景的前沿性能,包括面向用户的 AI 助手和高容量任务。阅读更多
- Claude Sonnet 3.7 与 Claude Code 2025 年 2 月 24 日 Sonnet 3.7 是首个混合推理模型,也是迄今为止我们最智能的模型。它在编码方面达到最先进水平,并在内容生成、数据分析和规划方面带来显著提升。阅读更多
可用性与定价
任何人都可以在 Claude.ai 上使用 Sonnet 4.6 与 Claude 聊天,支持网页、iOS 和 Android。
对于有兴趣构建智能体的开发者,Sonnet 4.6 可在 Claude Platform 原生使用,也可在 Amazon Bedrock、Google Cloud 的 Vertex AI 和 Microsoft Foundry 中使用。1M token 上下文窗口目前仅在 API 上以 beta 版提供。
Sonnet 4.6 的定价起始为每百万输入 token 3 美元、每百万输出 token 15 美元,通过提示缓存最高可节省 90% 成本,通过批处理可节省 50% 成本。了解更多信息,请查看我们的定价页面。要开始使用,只需通过 Claude API 使用 claude-sonnet-4-6。
使用场景
Sonnet 4.6 是一个强大而多用途的模型,面向日常使用、规模化生产,以及跨编码、智能体和专业工作流的复杂任务而构建。
Sonnet 4.6 可以生成近乎即时的响应,也可以进行扩展的逐步思考。API 用户还可以精细控制模型的思考投入。常见使用场景包括:
高级编码
Sonnet 4.6 在整个软件开发生命周期中提供前沿编码性能。从初始规划和实现,到调试、维护和大规模重构,它擅长对复杂的多文件代码库进行推理,生成精确实现,并以最少的往返交互进行迭代。
长时间运行的智能体
Sonnet 4.6 为自主 AI 工作流提供更出色的指令遵循、工具选择和错误纠正能力。它能够可靠处理需要持续连贯性和自适应决策的复杂多步骤任务,使其成为面向客户的智能体、内部自动化,以及需要在规模化场景下独立运行的生产级 AI 系统的理想基础。
浏览器与计算机使用
Sonnet 4.6 在计算机使用能力方面表现出色,能够可靠处理从竞争分析到采购工作流再到客户入门等任何基于浏览器的任务。基于使 Sonnet 成为首个使用计算机的前沿 AI 模型的基础,Sonnet 4.6 能以更高准确性和可靠性浏览数字环境,使企业能够自动化以往需要人工介入的工作流。
企业工作流
Sonnet 4.6 可处理金融、研究、内容和业务运营等领域的高容量、高风险专业工作流。它能够分析复杂金融数据,综合来自内部和外部来源的洞见,生成和编辑文档与电子表格,并以细腻和精准的方式产出有说服力的书面内容。
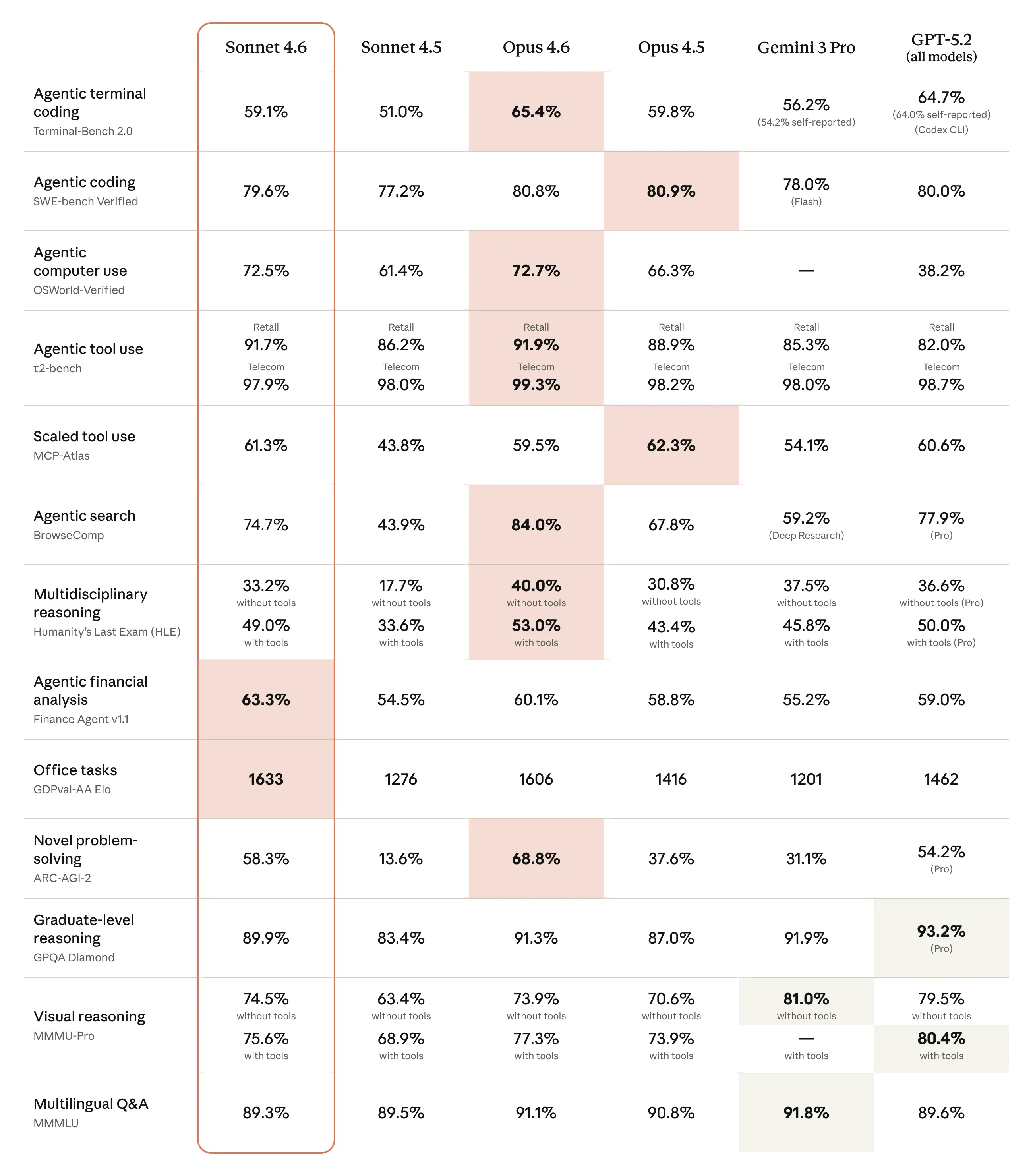
基准测试
Sonnet 4.6 在对真实世界部署最重要的基准测试中达到前沿性能,涵盖智能体式编码和工具使用、复杂推理以及长上下文任务。
信任与安全
我们对 Sonnet 4.6 进行了广泛测试和评估,并与外部专家合作,以确保其符合我们的安全性、安保性和可靠性标准。随附的模型卡深入介绍了安全性结果。
听听客户的评价
Claude Sonnet 4.6 一经推出,就已经在复杂代码修复方面表现出色,尤其是在必须跨大型代码库搜索时。对于大规模运行智能体式编码的团队,我们看到了很高的解决率,以及开发者所需要的一致性。
Claude Sonnet 4.6 生成了我们为 Rakuten AI 测试过的最佳 iOS 代码。规范符合度更高,架构更好,并且一次性调用了我们并未要求的现代工具。结果确实让我们惊讶。
Claude Sonnet 4.6 的性能成本比非同寻常——很难夸大 Claude 模型在近几个月进化得有多快。Sonnet 4.6 在我们的编排评估中表现更佳,能够处理我们最复杂的智能体式工作负载,而且你把 effort 设置推得越高,它的表现越会继续改善。
Claude Sonnet 4.6 在 Sonnet 4.5 表现不足的难题上能力明显更强,并且在通常需要 Opus 模型的自主性和智能体能力的任务上展现出实力。
Claude Sonnet 4.6 对绝大多数真实世界 PR 的表现远超其定位,并且在最困难的 bug 发现问题上相比 Sonnet 4.5 提升超过 10 分。对于真正要发布的代码,它已经成为我们的默认选择。
在我们的长周期编码评估中——每个功能都建立在上一个功能之上,而且你必须承受早期决策的后果——Sonnet 4.6 与 Opus 4.5 表现相当。token 更少。速度更快。对于大多数工程工作,从这里开始。
Claude Sonnet 4.6 在构建前端页面和数据报告时具有完美的设计品味,而且相比我们此前测试过的任何模型,它需要的手把手指导都少得多。
Claude Sonnet 4.6 更快、更便宜,也更有可能第一次就做对。这是一组令人意外的改进,我们没想到会在这个价位看到这样的表现。
Claude Sonnet 4.6 在我们关注的编码任务上基准表现接近 Opus 水平,并且相比前代在指令遵循和工具可靠性方面有明显提升。我们正在把 Sonnet 流量迁移到这个模型。
Claude Sonnet 4.6 显著改进了我们核心产品背后的答案检索——在我们的 Financial Services Benchmark 中,与 Sonnet 4.5 相比,我们看到答案匹配率显著跃升,并且在客户依赖的特定工作流上召回率更好。
Claude Sonnet 4.6 在 UI 布局方面可与最佳模型媲美,并大幅超过上一代 Sonnet。它是我们希望用来为用户构建应用的模型。
我们正在将大部分流量迁移到 Claude Sonnet 4.6。通过自适应思考和高 effort 设置,我们在除最困难分析任务之外的所有任务上都看到了 Opus 级性能,同时具备更高效、更灵活的特性。以 Sonnet 的定价来看,这对我们的工作负载来说是显而易见的选择。
Claude Sonnet 4.6 在我们的复杂保险计算机使用基准测试中达到 94%,是我们测试过的所有 Claude 模型中最高的。它能够对失败进行推理并自我纠正,方式是我们以前没有见过的。
Box 评估了 Claude Sonnet 4.6 在真实企业文档上的深度推理和复杂智能体任务中的表现。它展现出显著改进,在重推理问答中比 Claude Sonnet 4.5 高出 15 个百分点。
Claude Sonnet 4.6 在复杂应用构建和 bug 修复上提供前沿级结果。它正成为我们处理过去需要更昂贵模型才能完成的深度代码库工作的首选。
Claude Sonnet 4.6 在复杂多角色故事中的一致性确实令人印象深刻——它能让每个角色的声音保持鲜明差异,使我们的叙事更有生命力。
Claude Sonnet 4.6 处理复杂计算机使用的准确性给我们留下了深刻印象。在我们的评估中,它相比我们测试过的任何其他模型都有明显提升。
Claude Sonnet 4.6 在真正知识工作最重要的行为上表现出色,在我们的内部评估中得分很高,同时工具调用更少、工具错误更少。结果是一个能够更可靠地处理复杂多步骤请求,并产出更一致、更精致工作的 AI。
Claude Sonnet 4.6 在 OfficeQA 上达到 Opus 4.6 的性能。OfficeQA 衡量模型读取企业文档(图表、PDF、表格)、提取正确事实并基于这些事实进行推理的能力。对于文档理解工作负载来说,这是一次有意义的升级。
Claude Sonnet 4.6 实现了速度、质量与经济性的结合。我们尤其喜欢用于大型项目的 1M token 上下文。它以直观而周到的评论带来惊喜,能够审慎地提出异议,并真正理解其工作的目标。











