中文内容


公告
- 新品 Claude Opus 4.8 2026年5月28日 在编程、agentic 任务和专业工作方面更强,Opus 4.8 具备一致性和自主性,可持续处理长期运行的任务。阅读更多
- Claude Opus 4.7 2026年4月16日 Claude Opus 4.7 在编程、视觉和复杂多步骤任务方面带来更强性能。它在困难工作中更加彻底且一致,并在专业知识工作中取得更好结果。阅读更多
- Claude Opus 4.6 2026年2月5日 Claude Opus 4.6 是我们迄今能力最强的模型。在 Opus 4.5 智能水平的基础上,它为编程、agent 和企业工作流带来新的可靠性与精确度水平。阅读更多
- Claude Opus 4.5 2025年11月24日 Claude Opus 4.5 是我们迄今最智能的模型。它在编程、agent、计算机使用和企业工作流方面树立了新标准。Opus 4.5 是 AI 系统能力的一次重要进步。阅读更多
- Claude Opus 4.1 2025年8月5日 Claude Opus 4.1 是 Opus 4 的直接替代版本,为现实世界的编程和 agentic 任务提供更优性能与精确度。它能以更严谨的方式和对细节的更多关注处理复杂的多步骤问题。阅读更多
可用性与定价
对于希望在复杂任务上与我们最强大模型协作的商业用户和消费者,Opus 4.8 已在 Claude 面向 Pro、Max、Team 和 Enterprise 用户开放。
对于有兴趣构建需要前沿智能的 AI 解决方案的开发者,Opus 4.8 可在 Claude Platform 原生使用,也可在 Amazon Web Services、Google Cloud 和 Microsoft Foundry 中使用。
Opus 4.8 的定价起价为每百万输入 token 5 美元、每百万输出 token 25 美元;通过提示缓存最高可节省 90% 成本,通过批处理可节省 50%。如需了解更多信息,请查看我们的定价页面。要开始使用,请通过 Claude API 使用 claude-opus-4-8。
对于需要在美国运行的工作负载,提供仅限美国的推理服务,输入和输出 token 价格为 1.1 倍。了解更多。
使用场景
Opus 4.8 是一款高端模型,最适合用于以往模型无法处理、且性能至关重要的任务。它面向专业软件工程、复杂 agentic 工作流和高风险企业任务而构建。
借助自适应思考,Opus 4.8 会根据任务复杂度自动调整所使用的思考量,在更难的问题上投入更多时间,并对较简单的问题快速响应。常见使用场景包括:
高级编程
Opus 4.8 能在最少监督下可靠交付可用于生产的代码。它会谨慎规划,以持续投入运行更长时间,并在更大型代码库中可靠运作。它能发现自身错误,因此资深工程师可以放心委派最困难的编程工作。
正文:AI agent
Opus 4.8 支撑生产级 agentic 工作流,以一致的可靠性编排复杂的多工具任务。它会审慎规划,利用记忆在不同会话间学习,并在最少监督下推动长期运行的工作向前进展。
企业工作流
Opus 4.8 为企业工作流树立标准,能够跨会话保留上下文,以专业的完成度和在电子表格、幻灯片及文档方面的强劲表现,端到端管理复杂的多日项目。
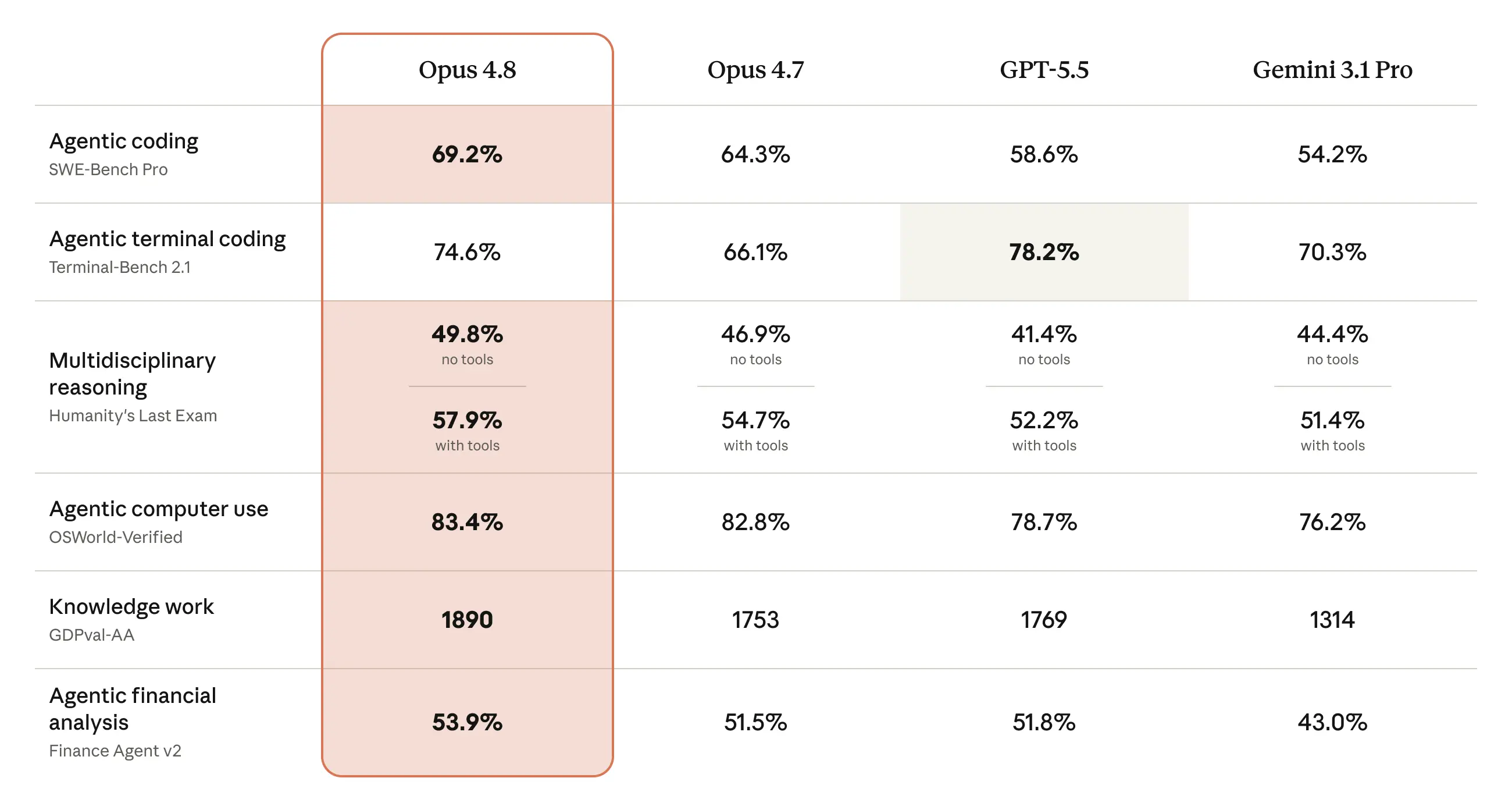
基准测试
Claude Opus 4.8 是我们能力最强的通用可用模型,在编程、agentic 和知识工作能力方面达到前沿水平。
信任与安全
广泛的测试和评估确保 Opus 4.8 的发布符合 Anthropic 在安全性、安保性和可靠性方面的标准。随附的系统卡深入介绍了安全结果。
听听客户怎么说
Claude Opus 4.8 的判断力明显更好。在 Claude Code 中,它会提出正确的问题,发现自身错误,在计划不合理时提出异议,并在进行重大更改前,围绕复杂的多服务探索建立信心。它是一个非常适合用于构建的模型。
在我们的 Super-Agent 基准测试中,Claude Opus 4.8 是唯一能端到端完成所有案例的模型,在成本相当的情况下超过了此前的 Opus 模型和 GPT-5.5。对于翻译、深度研究、幻灯片制作和分析领域的 agent 产品,它提供了强大的可靠性。
在 CursorBench 上,Claude Opus 4.8 在各个努力级别上都超过了此前的 Opus 模型。工具调用的效率明显更高,以更少步骤实现同等智能,并能完成端到端任务。
Claude Opus 4.8 在我们的 Legal Agent Benchmark 上取得了有记录以来的最高分,也是首个在全通过标准下总体突破 10% 的模型。对于实质性法律工作而言,这种准确率提升会直接转化为客户可以放心交由其处理的真实律师工作量。
与 Opus 4.7 相比,Claude Opus 4.8 像是一次重大的使用体验更新:更快、更易协作,并且在长会话中更擅长保持上下文和风格方向。Opus 4.8 是我在需要同时兼顾语气、品味和技术执行的工作中一直信任的模型。
Claude Opus 4.8 是我们测试过的最强计算机使用和浏览器 agent 模型,在 Online-Mind2Web 上得分 84%,相较 Opus 4.7 和 GPT-5.5 都有显著提升。它能够以客户 agent 工作负载实现端到端可靠性所需的方式,保持反思并专注于任务。
Claude Opus 4.8 能清晰使用工具,并以我们的自主工程工作负载在无人值守情况下持续运行所需的一致性遵循指令。它改进了 Opus 4.6,并修复了我们在 Opus 4.7 中看到的评论冗长和工具调用问题。Anthropic 的这次发布会直接转化为基于 Devin 构建的工程师更快的能力提升。
在我们的长期运行评估中,Claude Opus 4.8 的分析质量始终高于此前的 Opus 模型。它完成得更快,并生成了更丰富、信息密度更高的输出。总体而言,信噪比明显更好。最大的差异点是 Opus 4.8 倾向于主动标记分析输入和输出中的问题,而其他模型通常会遗漏这些问题,留给用户发现。
在 CoCounsel Legal 中,与此前的 Opus 模型相比,Claude Opus 4.8 在一致性和推理质量方面带来了有意义的提升。对于客户所依赖的高风险专业工作流,这种可靠性很重要。在我们为法律和税务专业人士构建信托级 AI 系统时,这类进步有助于提高现实工作流中可信 AI 性能的标准。
Claude Opus 4.8 为企业 AI 设定了新标杆。在 Databricks 面向数据和知识工作的 AI agent Genie 中,新的 Opus 模型带来了 agentic 推理的阶跃式变化,能够比任何此前的 Opus 更快处理更深入的多步骤问题。其多模态能力还让 Genie 能直接对 PDF、图表和其他非结构化内容进行推理,token 成本比 Opus 4.7 低 61%。
在 Hebbia orchestrator 的金融文档工作流中,Claude Opus 4.8 提供了与 Opus 4.7 同样强劲的质量,同时在引用精确度和检索 token 效率方面明显更好,非常适合客户每天处理的这类密集申报文件。
常见问题
我应该何时使用 Claude Opus 4.8?
我们提供覆盖速度、价格和性能不同范围的 Claude 模型。Opus 4.8 是我们迄今能力最强的通用可用模型。我们建议在需要前沿智能的最苛刻使用场景中使用 Opus 4.8,尤其是可用于生产的代码、复杂 AI agent 和复杂文档创建。
使用 Claude Opus 4.8 需要多少费用?
定价取决于你希望如何使用 Opus 4.8。如需了解更多信息,请查看我们的定价页面。
