中文内容
该解决方案基于包括 PyTorch、Hugging Face Transformers 和 Liger Kernels 在内的开源工具构建。作者还要感谢 Aiham Taleb、Arefeh Ghahvechi、Manav Choudhary、Rohit Thekkanal、Daz Akbarov、Jamila Jamilova、Ross Povelikin、Almas Moldakanov、Christelle Xu 和 Ivan Khvostishkov 的贡献,使该项目得以实现。
Azercell Telecom LLC 是阿塞拜疆领先的电信服务提供商,希望在 Amazon SageMaker AI 上构建一个面向电信用例和客户交互式聊天机器人的阿塞拜疆语大语言模型(LLM)。挑战在于:将基础模型(FM)适配到一种形态丰富、训练数据有限且尚无高效阿塞拜疆语 LLM 训练现成蓝图的语言。在为期六周的合作中,Azercell 与 AWS Generative AI Innovation Center 合作,在 Amazon SageMaker AI 上建立了一个可用于生产的框架,通过在 ml.p5.48xlarge 实例上进行内核级优化,实现了训练吞吐量提高 23%、GPU 峰值内存使用量降低 58%。该框架还通过自定义分词器将每个词对应的 token 数提升了 2 倍,实际上使可放入模型上下文窗口的阿塞拜疆语文本量翻倍。如果你处理的是低资源
解决方案概述
该框架实现了三个连续阶段,每个阶段都会生成供下一阶段使用的工件。
- 阶段 1:分词器开发为阿塞拜疆语构建高效分词器。我们评估了三种方法(基线英语优化分词器、词汇表扩展和自定义单语分词器),并通过标准化指标衡量编码效率。自定义单语分词器取得了最佳结果,与基线相比,每个单词所需的 token 数量减少了一半。
- 阶段 2:持续预训练(CPT)通过在 Amazon SageMaker AI 训练作业上使用分布式训练和 Liger Kernel 优化,使 FM(Llama 3.2 1B)适应并理解阿塞拜疆语。这使得在相同硬件上可以使用更大的批量大小并获得更高的吞吐量。虽然这个 1B 规模的概念验证并不需要分布式训练,但随着 Azercell 扩展到更大的模型,分布式训练将至关重要。
- 阶段 3:使用 Low-Rank Adaptation(LoRA)的监督微调将预训练模型转变为对话助手。经过 CPT 后,模型可以预测阿塞拜疆语 token,但无法进行对话。阶段 3 应用 LoRA,这是一种参数高效的微调方法,可显著减少可训练参数。
训练阶段(CPT 和 LoRA 微调)以 Amazon SageMaker AI 训练作业的形式运行,这些作业从 Amazon SageMaker Unified Studio 启动,每个作业都指向一个自定义训练脚本。每个作业都会预置全新的 Amazon Elastic Compute Cloud(Amazon EC2)实例,并在完成后终止,因此你只需为实际计算时间付费,不会产生空闲集群成本。
下图展示了模块化架构,其中每个阶段都可以独立优化。Tokenizer 的改进会惠及每个后续训练阶段,并且 CPT 配置可在各项微调任务之间迁移。
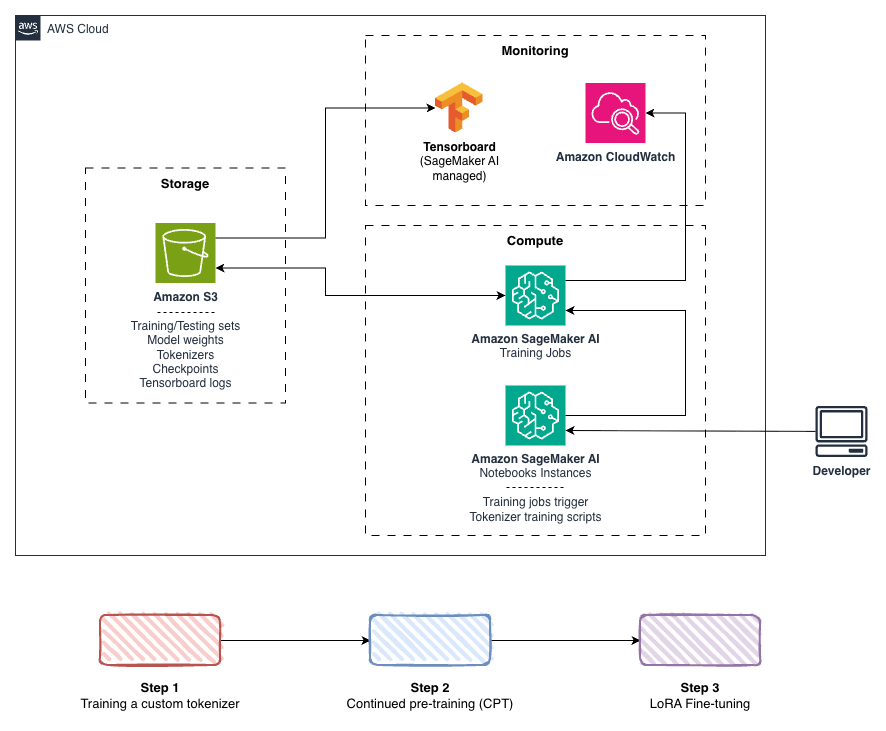
图 1. 训练流水线架构。操作人员从 Amazon SageMaker AI Notebook Instances 启动训练作业。训练数据和模型工件存储在 Amazon Simple Storage Service(Amazon S3)中。训练指标通过 Amazon SageMaker AI 中的 TensorBoard 进行跟踪,系统指标则通过 Amazon CloudWatch 捕获。
开发阿塞拜疆语 Tokenizer
像阿塞拜疆语这样的语言形态丰富,单个词可以通过后缀编码语法意义,而英语则需要用多个词来表达。然而,针对英语优化的标准分词器会将这些复杂的词形切分得支离破碎。例如,如图 2 所示,将“kitablardan”(意为“从书中”)拆分为多个子词 token,这会减少固定大小上下文窗口中实际可容纳的内容。
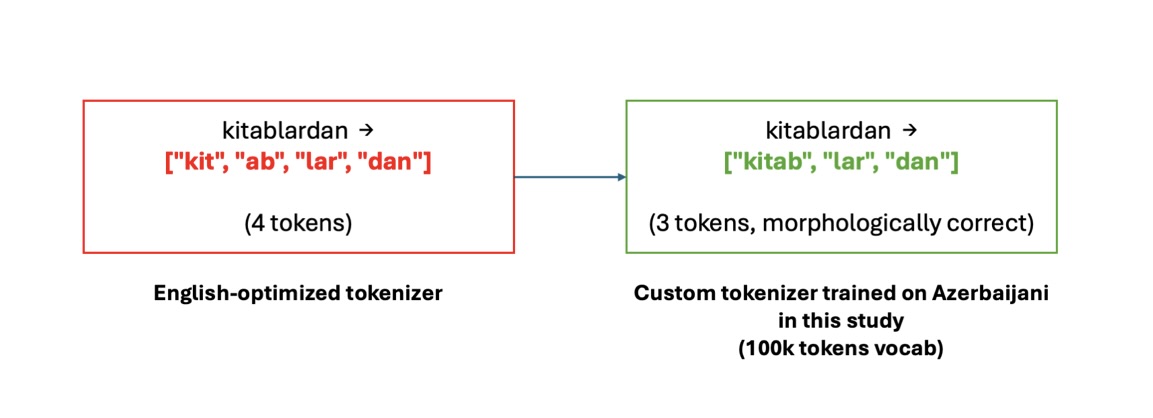
图 2. 阿塞拜疆语文本的基线分词与自定义分词对比,显示了 token 碎片化程度的降低。
为了解决这个问题,我们使用字节级字节对编码(Byte-Level Byte-Pair Encoding,BBPE)算法在阿塞拜疆语文本上训练了一个自定义分词器,该算法会迭代地将最频繁的字节对合并为词表条目。从原始字节而非预定义字符集开始,可以完全覆盖阿塞拜疆语特有字符,而无需手动定义字母表。我们尝试了从 50k 到 100k token 不等的词表规模,以找到合适的平衡:词表太小,分词器会过度切分词语;词表太大,稀有 token 则缺乏足够的训练信号。
我们使用 Hugging Face tokenizers 库训练了自定义 tokenizer,其配置与原生 Llama 3.2 tokenizer 相同,仅词表大小不同。在训练并评估了多个不同词表大小的 tokenizer 后,我们最终选择了 100k token 的词表。为验证自定义 tokenizer 没有牺牲建模质量,我们在继续预训练后使用 Bits-Per-Byte(BPB)而非困惑度来比较模型,因为 BPB 通过在字节层面衡量预测质量,对词表差异进行了归一化。使用自定义 tokenizer 的模型在验证集上的 BPB 为 0.5795,而基线为 0.6830,这证实了编码效率的提升并未带来质量上的取舍。
除了保持建模质量之外,定制 tokenizer 还带来了显著的实际效率提升。编码效率可以通过 fertility score(每个词的平均 token 数)来量化,数值越低表示编码效率越高。基线 Llama 3.2 tokenizer 对阿塞拜疆语单词的平均值为每词 3.22 个 token,而定制的单语 tokenizer 达到 1.59,实现了编码效率 2 倍提升。对于 Llama 3.2 的 128k-token 上下文窗口,这会转化为实际容量差异:使用基线 tokenizer 约可容纳 40k 个词,而使用优化后的 tokenizer 约可容纳 80k 个词——实际上使模型一次可考虑的内容量翻倍。
继续预训练
继续预训练使 FM(Llama 3.2 1B)适应理解阿塞拜疆语。该阶段的主要瓶颈是 GPU 内存:优化内存利用率直接决定了硬件投资中有多少能转化为训练吞吐量。我们在 ml.p4d.24xlarge(8× NVIDIA A100 GPUs)和 ml.p5.48xlarge(8× NVIDIA H100 GPUs)实例上都进行了基准测试。以下部分介绍了两个经过基准测试的优化方法:使用 PyTorch 的 Fully Sharded Data Parallel(FSDP)进行分布式训练,以及集成 Liger Kernel。
使用 Fully Sharded Data Parallel(FSDP)进行分布式训练
模型的内存占用不仅包括权重,还包括梯度、优化器状态和激活值。对于 Llama 3.1 8B 等较大的模型,在混合精度下,这些组件可能超过 100 GB。我们在 1B 模型上开发并验证了分布式训练设置,因此扩展到更大的架构只需要更改配置,而无需重新设计流水线。标准的 Distributed Data Parallel(DDP)会在每个 GPU 上复制完整模型,这限制了可实现的批量大小和模型规模。FSDP 会在多个 GPU 之间对参数、梯度和优化器状态进行分片,并在每个计算步骤中动态收集所需内容。这将 ml.p4d.24xlarge 上每个 GPU 的模型状态内存从 9.23 GB 降至 1.17 GB,为更大的批量大小释放了余量。
Liger Kernel 集成
Liger Kernels 是基于 Triton 的内存高效型常见 LLM 操作实现,它们将多个操作融合为单次 GPU 内核启动,在产生数值等价结果的同时减少中间内存分配。它们支持包括 Llama 在内的几种流行模型架构。我们建议你在采用之前验证其与你的架构的兼容性。
集成只需极少的代码改动:在实例化之前,通过一次函数调用即可使用优化内核对模型进行补丁处理,并且 Liger Kernels 可与 PyTorch FSDP 配合使用,无需修改分布式训练设置。我们使用 PyTorch Profiler 验证了执行的正确性,确认了跟踪中的融合操作。下表总结了在两种实例类型上每个优化步骤的累积影响。请注意,未对 p5 实例上的 DDP 内存和吞吐量进行基准测试,因为 FSDP 是目标配置。
Metric DDP FSDP FSDP + Liger Max batch size per GPU on ml.p4d.24xlarge (8× NVIDIA A100 GPUs) 2 4 14 Max batch size per GPU on ml.p5.48xlarge (8× NVIDIA H100 GPUs) 4 10 18 Peak GPU memory incl. activations (GB) on ml.p5.48xlarge — 64 27 Training throughput per GPU (tokens/s) on ml.p5.48xlarge — 63,771 78,319在 ml.p4d.24xlarge 上,完整优化栈使最大批量大小相比 DDP 提升了 7 倍。在 ml.p5.48xlarge 上,将 Liger Kernels 添加到 FSDP 后,峰值 GPU 内存下降了 58%,每 GPU 吞吐量提高了 23%。
预训练设置
第 1 阶段的每种分词器配置都贯穿 CPT 全流程,以比较收敛行为和下游质量。使用自定义阿塞拜疆语分词器(100k 词表)时,训练语料库约为 25 亿个 token。
该自定义训练脚本支持可配置的上下文窗口、BFloat16 混合精度、使用 AdamW 的余弦学习率调度,以及自动检查点保存到 Amazon S3 以实现容错。我们将上下文窗口设置为 2,048 个 token,因为分词后超过 90% 的训练样本长度低于该值,不过该配置最高支持模型原生的 128k token 限制。
当向词汇表添加新 token 时,CPT 采用两阶段方法。在第一阶段,冻结模型主干,仅训练嵌入层。这会使新 token 表示适配到模型现有的内部空间,而不会破坏预训练知识。在第二阶段,解冻参数以进行完整训练,使模型能够深入学习阿塞拜疆语的语言模式。下表展示了使用阿塞拜疆语自定义 tokenizer(100k 词汇表)的训练配置。训练使用了两个 ml.p4d.24xlarge 实例(共 16 个 NVIDIA A100 GPU),并采用 FSDP 和 Liger Kernel 优化。
Parameter Phase 1: Embedding Adaptation Phase 2: Full Training Frozen backbone Yes No Learning rate 0.0032 0.0024 Batch size per GPU 14 14 Steps 5,000 15,000 Training time ~11,400 seconds (~3.2 hours) ~43,000 seconds (~11.9 hours)在完整训练阶段采用较低的学习率,可以保留嵌入适配期间获得的知识。在有效批量大小为 224(每个 GPU 14 × 16 个 GPU)且上下文窗口为 2,048 个 token 的情况下,每个训练步骤大约处理 45 万个 token,在此配置下估算每个 epoch 约需 4.3 小时。在 ml.p5.48xlarge 上,更高的单 GPU 吞吐量和更大的批量大小将进一步缩短每个 epoch 的时间。
使用 LoRA 进行监督微调
经过 CPT 后,模型可以流畅地预测下一个阿塞拜疆语 token,但它没有对话结构的概念。给定一个问题时,它会生成看似合理的延续内容,而不是有帮助的答案。LoRA 通过冻结预训练权重,并训练注入到模型注意力层和前馈层中的小型低秩分解矩阵,高效地弥合了这一差距。LoRA 不是更新完整的权重矩阵,而是训练两个更小的矩阵,其乘积近似于完整更新——从而将可训练参数减少到总参数量的一小部分。下表总结了 LoRA 微调配置。
Parameter Rank Alpha Dropout Target modules Max sequence length Value 64 28 0.05 q, k, v, o projections; gate, up, down projections 1,024这种紧凑的占用规模意味着微调可在单个 ml.g5.8xlarge 实例(1 块 NVIDIA A10G GPU)上运行,并在数分钟内完成。微调使用了约 2,000 个单轮阿塞拜疆语问答对,采用 Hugging Face 的 SFTTrainer,学习率为 1e-4——高于 CPT 的学习率,因为 LoRA 适配器是随机初始化的,并且受益于更强的梯度更新。
训练采用 Llama 风格的聊天模板,并使用仅针对助手的损失掩蔽:模型只会因预测助手响应 token 和轮次结束 token(<|eot_id|>)而受到惩罚,而用户提示和模板分隔符则不计入损失。因此,模型将其学习能力集中在生成合适的响应上,而不是记忆用户输入模式。
结果与验证
持续预训练使用了约 25 亿个 token,并采用自定义阿塞拜疆语分词器;微调则使用了 2,000 个问答对。该框架在四个维度上实现了可衡量的改进:
- 通过自定义分词实现 2× 编码效率 自定义单语分词器将 fertility 分数减半(从每词 3.22 个 token 降至 1.59 个 token),实际使模型 128k-token 上下文窗口中可容纳的阿塞拜疆语内容翻倍。BPB 分数为 0.5795,而基线为 0.6830,证实了这一提升并未牺牲建模质量。
- 显著的内存与吞吐量优化 Fully Sharded Data Parallel (FSDP) 分片和 Liger Kernel 集成使同一硬件上的批量大小得以增大,相较各自的 DDP 基线,在 ml.p4d.24xlarge 上最高可达 7×,在 ml.p5.48xlarge 上最高可达 4.5×,同时将 GPU 峰值内存降低 58%,并将每 GPU 吞吐量提高 23%。
- 可用于生产的可扩展基础设施 在 ml.p4d.24xlarge 和 ml.p5.48xlarge 实例上验证的配置,为 Azercell 提供了一个灵活的基础,可随训练需求增长而扩展;其分布式设置经过设计,使迁移到更大模型时仅需更改配置。
- 连贯的阿塞拜疆语生成:现成的 Llama 3.2 1B 在使用阿塞拜疆语提示时会偏向重复且不连贯的输出,这是代表性不足语言的一种常见失效模式。经过微调的模型能够生成简洁、语义连贯的回应,体现出清晰的阿塞拜疆语理解能力。下表以 Azercell 提供的一个示例提示对此进行了说明。
学习一门新语言不仅会拓展交流机会。相反,除了学习一门新语言的不同目的之外,学习者自己也开始学习一门新语言。
语言学习还会促使学习一门新语言的方向和经验得到扩展。在学习一门新语言的方向和经验得到扩展之后,学习一门新语言的方向和经验的扩展……
Learning a new language not only expands communication opportunities. On the contrary, it also leads people who learn a language to approach language learning with different goals, and they themselves begin the process of learning a new language. Language learning also contributes to the expansion of directions and experiences related to learning a new language. After expanding these directions and experiences, the development of approaches and experiences in learning a new language continues… Fine-tuned Llama 3.2 1B Yeni bir dil öyrənmək yalnız ünsiyyət imkanlarını genişləndirmir, həm də yeni dostlar və əlaqələr yaradır. Learning a new language not only expands communication opportunities but also creates new friendships and connections.结论
在本文中,我们展示了 Azercell 和 AWS Generative AI Innovation Center 如何在 Amazon SageMaker AI 上构建用于训练阿塞拜疆语语言模型的框架。这个三阶段流程(自定义分词、结合 FSDP 和 Liger Kernel 优化的继续预训练,以及 LoRA 微调)将通用基础模型转化为阿塞拜疆语对话助手,同时最大化 GPU 利用率。Azercell 现在已能独立运行该框架,其方法论支持更大规模的语料库、扩展的架构以及更广泛的用例。要了解更多信息,请浏览以下资源:
- Amazon SageMaker AI —— 用于训练和部署的托管式机器学习服务
- AWS Generative AI Innovation Center —— 协作式 AI 开发项目
- Amazon SageMaker AI 中的分布式训练 —— 分布式训练概念
- PyTorch FSDP 教程——实现指南
- Liger Kernels——内存高效的内核实现
- Hugging Face Tokenizers——分词器训练库
- Llama 3.2 1B——基础模型
要探索实施类似解决方案,请联系您的 AWS 客户团队或访问 AWS Generative AI Innovation Center。如果您正在为低资源语言训练 LLM,或在 SageMaker AI 上优化 GPU 利用率,我们很乐意听取您的意见。请在评论中分享您的想法和问题。
关于作者





