中文内容
在 Amazon SageMaker AI Inference 上大规模部署大型语言模型(LLMs)时,可观测性成为任何生产级机器学习(ML)策略的关键支柱。与返回确定性输出的传统软件不同,LLMs 会生成可变的、自由形式的响应,难以用标准指标进行验证。随着输入分布发生变化,LLM 输出质量可能会随时间改变,而质量监控有助于及早发现这些变化。对于生成式 AI 工作负载,可观测性还包括模型服务基础设施,在其中,不可预测的 token 消耗、GPU 内存压力和延迟峰值会使容量规划和成本控制成为一个不断变化的目标。
面向 LLM 推理的全面可观测性方法必须处理两个不同但互补的维度:模型服务基础设施(数量)和 LLM 质量。数量监控侧重于推理基础设施的运行健康状况,跟踪请求吞吐量和资源利用率。这些指标有助于发现瓶颈、合理调整计算资源规模并控制成本。质量监控侧重于 LLM 本身的性能,评估响应准确性、合规性以及随时间变化的一致性。
大多数团队会分阶段构建 LLM 可观测性。第一阶段是建立对核心运营指标的可见性,例如延迟、错误和资源利用率。这些信号可确认推理端点的可靠性。下一阶段通过抽样和评估加入 LLM 质量维度,从而暴露模型漂移、性能退化或生成响应中的异常行为等问题。
在这两个维度都到位后,你可以引入阈值和自动化告警,将基础设施信号与质量信号结合起来。随着时间推移,这一实践会扩展到跨模型和配置的比较分析,以便持续调优成本、性能和输出质量。数量指标和质量指标相互依赖:一个端点在运营层面可能看起来健康,却生成质量差或不安全的响应;也可能输出高质量结果,但运行在过度配置的基础设施上而效率低下。当这两个维度被共同监控、关联和优化时,生产级 LLM 可观测性便得以形成。
本文展示了一套全面的可观测性解决方案,该方案使用 Amazon Managed Grafana 仪表板,为部署在带有推理组件的 Amazon SageMaker AI 端点上的 LLM 提供质量与数量两方面的整体视图。
工作流架构
为了全面了解 LLM 在数量和质量两个监控维度上的表现,我们使用三项核心 AWS 服务构建了一个解决方案,每项服务都因其在 LLM 可观测性中的特定作用而被选用。以下高层数据流图展示了三个核心组件:带有推理组件的 Amazon SageMaker AI 端点、Amazon CloudWatch 和 Amazon Managed Grafana。
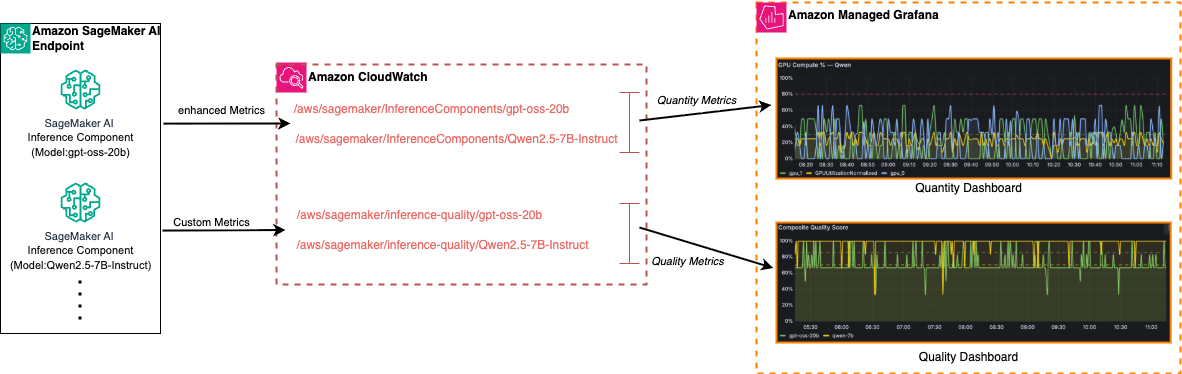
Amazon SageMaker AI Inference Components 作为模型托管层。单个 SageMaker AI 端点可以托管多个推理组件,每个组件运行不同的 LLM(例如,如前述架构中所示的 gpt-oss-20b 和 Qwen2.5-7B-Instruct)。推理组件使你能够在共享基础设施上部署、扩展和管理多个模型,同时为流量路由、扩展策略和指标归因保持按模型隔离。
Amazon CloudWatch 充当集中式指标存储。它从每个推理组件接收两种不同的数据流:增强指标和自定义质量指标。当您在端点配置上启用增强指标时,SageMaker AI 会自动发布这些指标。这些指标包括实例级、容器级和每 GPU 维度,让您能够细粒度地了解每个模型的调用次数、延迟、错误率以及 GPU/CPU 利用率。增强指标会记录到 /aws/sagemaker/InferenceComponents/<model-name> 命名空间(例如 /aws/sagemaker/InferenceComponents/gpt-oss-20b)。有关详细信息,请参阅 Amazon SageMaker AI 增强指标文档和增强指标深度解析博客文章。
自定义质量指标捕获 LLM 输出质量,例如综合质量评分、安全评分和评估延迟。这些指标会发布到单独的用户配置 CloudWatch 命名空间 /aws/sagemaker/inference-quality/<model-name>,从而使质量信号与运营指标清晰分离。下表总结了两个 CloudWatch 指标命名空间。
CloudWatch Metric Namespace Captures Purpose /aws/sagemaker/InferenceComponents/ Enhanced metrics: instance-level, container-level, and per-GPU dimensions Provides granular visibility into invocation counts, latency, error rates, and GPU/CPU utilization per model /aws/sagemaker/inference-quality/ Custom quality metrics: composite quality scores, safety scores, and evaluation latency Captures LLM output quality signals, kept cleanly separated from operational metricsAmazon Managed Grafana 提供可视化层,并将 CloudWatch 用作其原生数据源。在本文中,我们介绍了两个专用仪表板,用于呈现 SageMaker AI 端点 LLM 数量和质量指标,如以下屏幕截图所示。
Grafana 基于数量的仪表板会显示每个推理组件的 GPU 内存利用率、CPU 使用率和调用指标。Grafana 基于质量的仪表板会显示综合质量评分、安全性评分和质量评估延迟,并在不同模型之间进行比较,如下图所示。你可以根据业务或应用场景创建新的仪表板,从而扩展 Grafana 仪表板。
数量监控
数量监控可让你对 SageMaker AI 端点上提供服务的 LLM 获得运营可见性。如果没有它,你可能会无法掌握流量模式、资源饱和度、成本归因和扩展行为,而所有这些都会直接影响可用性和支出。对于使用推理组件的多模型端点,数量监控可以回答关键运营问题:每个模型正在处理多少请求?GPU 规格是否合适,还是过度配置?哪个模型在推动成本?
除基础设施指标外,数量监控还可帮助你评估 LLM 推理组件在性能与可靠性、资源利用率以及组织特定的任何业务指标方面的运营健康状况和业务影响。这些视图共同显示延迟发生的位置、成本增加是由流量增长还是低效的 GPU 分配所驱动,以及扩展策略是否在适当地响应需求。
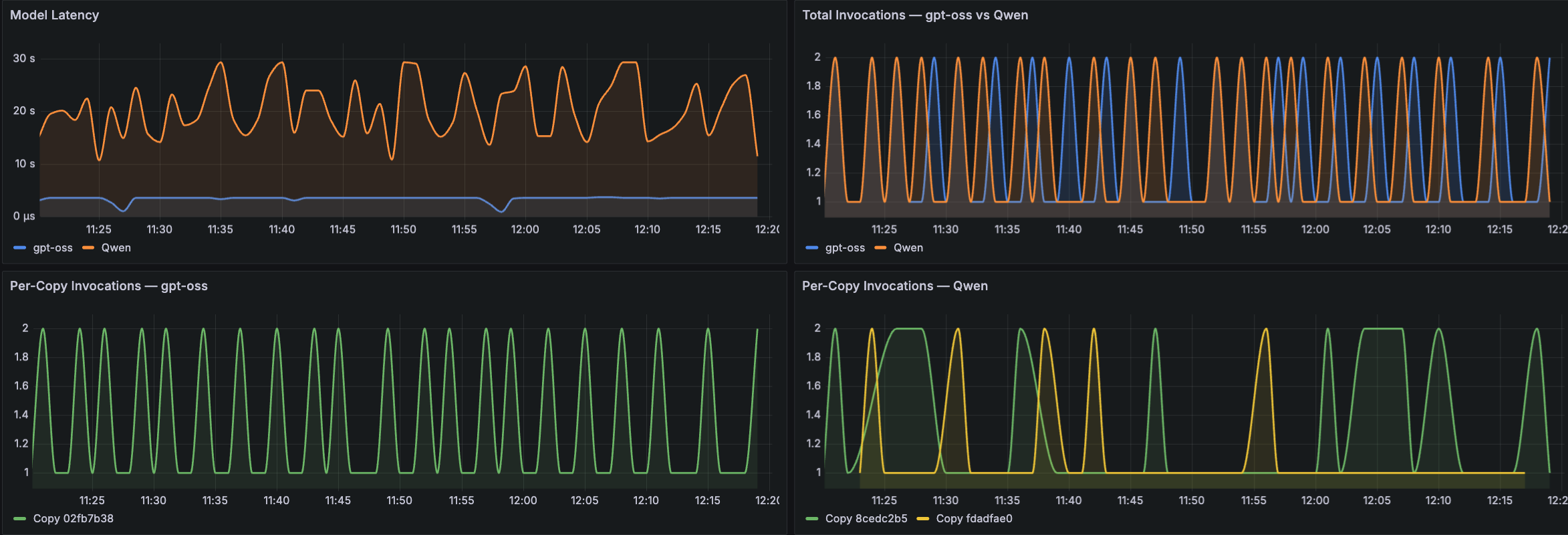
以下 Amazon Managed Grafana 仪表板示例将这些数量监控维度应用于三个关键领域。第一组面板涵盖 LLM 调用和延迟。如下方 Grafana 仪表板输出示例所示,面板以时间序列趋势显示 Model Latency,显示用于比较模型(例如 gpt-oss 与 Qwen)的 Total Invocations,并按每个模型细分显示 Per-Copy Invocations。这些面板可帮助运维人员了解请求吞吐量模式、识别延迟峰值,并比较不同模型副本之间的调用分布。
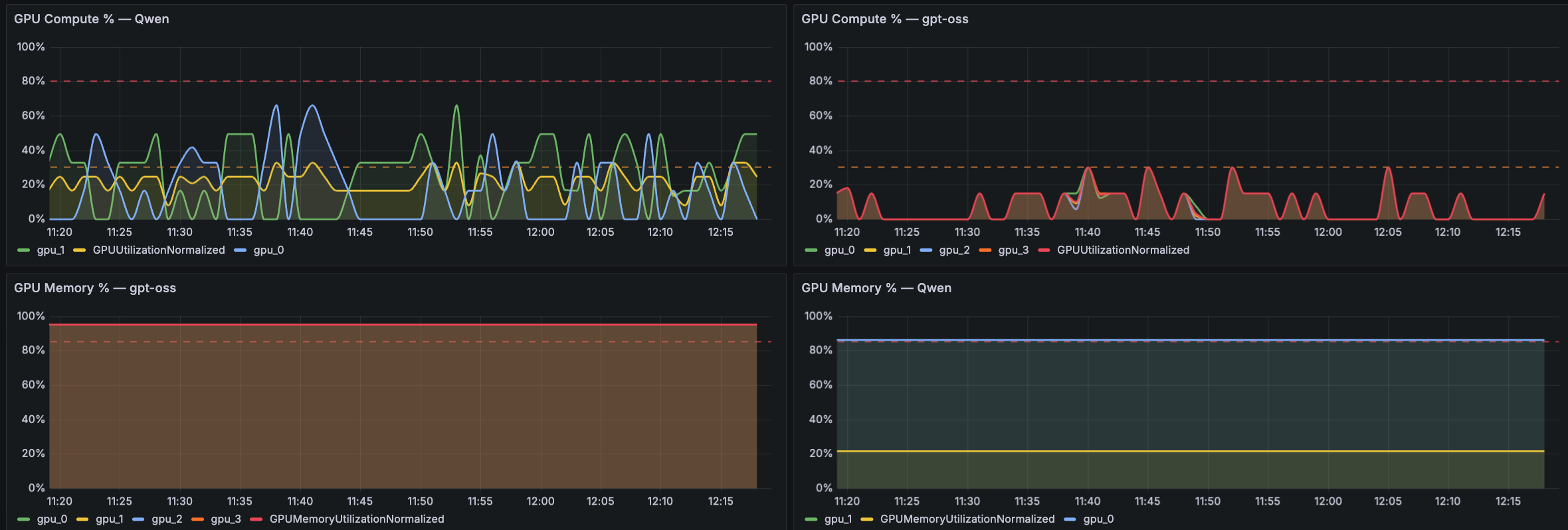
下一个面板侧重于 GPU 计算和内存利用率。以下 Grafana 仪表板示例展示了两个模型(例如 Qwen 和 gpt-oss)的 GPU Compute 百分比和 GPU Memory 百分比面板。这种跨模型比较有助于机器学习工程师和站点可靠性工程师(SRE)快速判断性能问题是受 GPU 计算限制还是受内存限制,以及某个模型是否在共享基础设施上消耗了不成比例的资源。
第三组面板提供端点使用情况和成本详情。以下 Cluster Overview and Cost Grafana 仪表板示例显示 Used GPUs 与 Free GPUs 以及 Total Instances,用于可视化集群容量,同时包含按模型划分的 Cost/hour 面板(例如 gpt-oss 和 Qwen)。该视图显示哪个模型在驱动成本、GPU 是否过度预置或已饱和,以及自动扩缩策略是否正在响应需求。
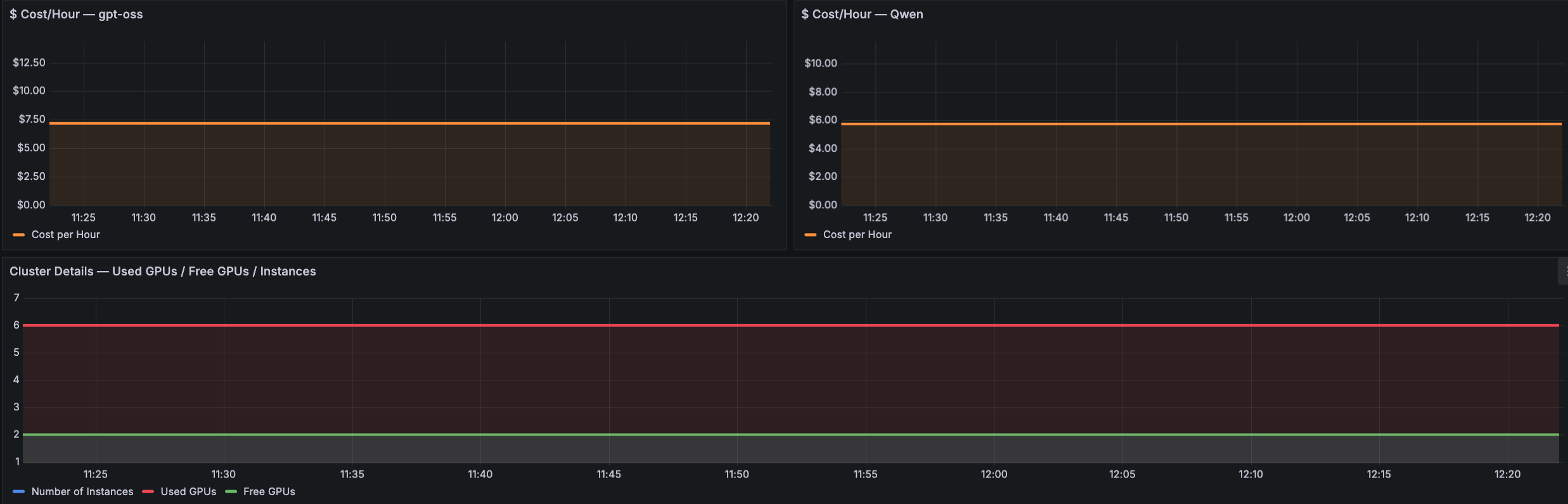
下表总结了 Grafana 仪表板中涵盖的三个数量监控领域,以及它们关联的指标和用途:
Metric Type Dashboard Metric Names Captures Purpose Model Invocations & Latency Model Latency, Total Invocations (gpt-oss vs Qwen), Per-Copy Invocations (gpt-oss), Per-Copy Invocations (Qwen) Request throughput, response time, and per-copy invocation distribution Identify latency spikes, compare model throughput, and understand invocation load balancing across copies GPU Compute & Memory Utilization GPU Compute % (Qwen), GPU Compute % (gpt-oss), GPU Memory % (Qwen), GPU Memory % (gpt-oss) Per-model GPU compute and memory utilization percentages Determine if issues are GPU-compute-bound or memory-limited, and detect disproportionate resource consumption across models Endpoint Usage & Cost Used GPUs / Free GPUs / Instances, Cost/hour (gpt-oss), Cost/hour (Qwen) Cluster capacity, GPU allocation status, and per-model hourly cost attribution Identify cost drivers, detect over-provisioned or saturated GPUs, and validate auto scaling responsiveness这些仪表板共同为运维人员提供了一个单一视图,用于关联端点上所服务各模型的成本、容量和利用率。要在您的环境中设置这些仪表板,请按照 AWS samples GitHub 仓库示例笔记本操作,并扩展该解决方案,以创建符合您组织需求的仪表板。
监控质量
数量指标可以告诉你 LLM 服务基础设施是否健康,而质量指标则告诉你 LLM 是否仍按预期运行。由于输入提示分布的变化、概念漂移或现实世界条件的变化,LLM 性能可能会随着时间推移而悄然下降。与延迟激增或 500 错误不同,质量下降很少会触发传统告警。
质量监控通过评估对业务至关重要的各个维度上的模型输出来解决这一问题:响应质量(与用户查询的相关性、事实准确性、完整性和一致性)、安全与合规(有害内容检测、偏见监控、隐私合规和监管遵从)、用户体验质量(有用性、清晰度、恰当的语气和多轮对话连贯性),以及特定领域质量(专业领域的技术准确性、Retrieval Augmented Generation (RAG) 应用的引用质量,以及编程助手的代码正确性)。这些维度共同帮助治理团队执行护栏机制,帮助产品负责人跟踪面向用户的质量随时间的变化,并帮助数据科学家判断质量下降是否由特定提示模式、模型更新或数据分布变化引起。
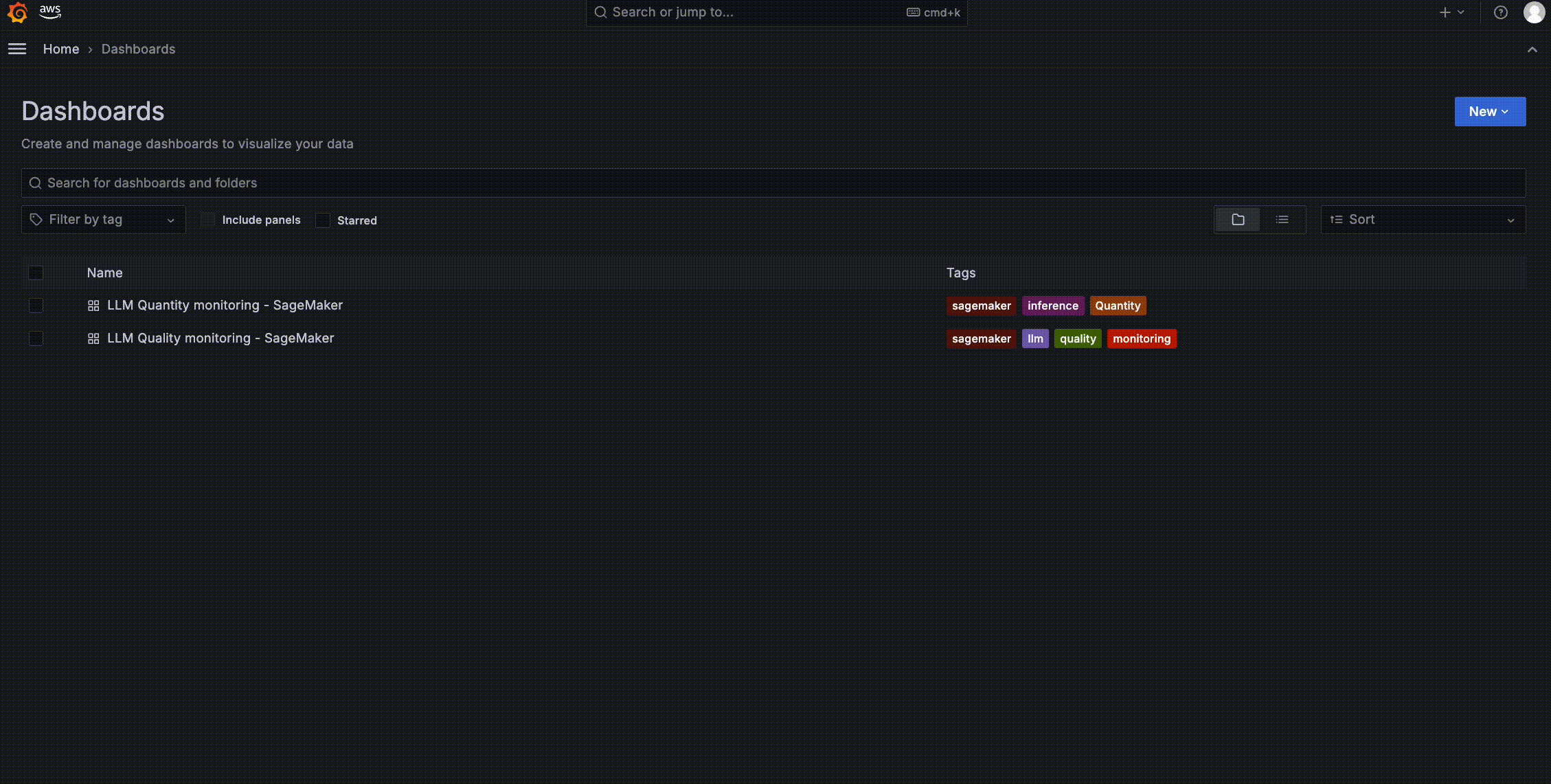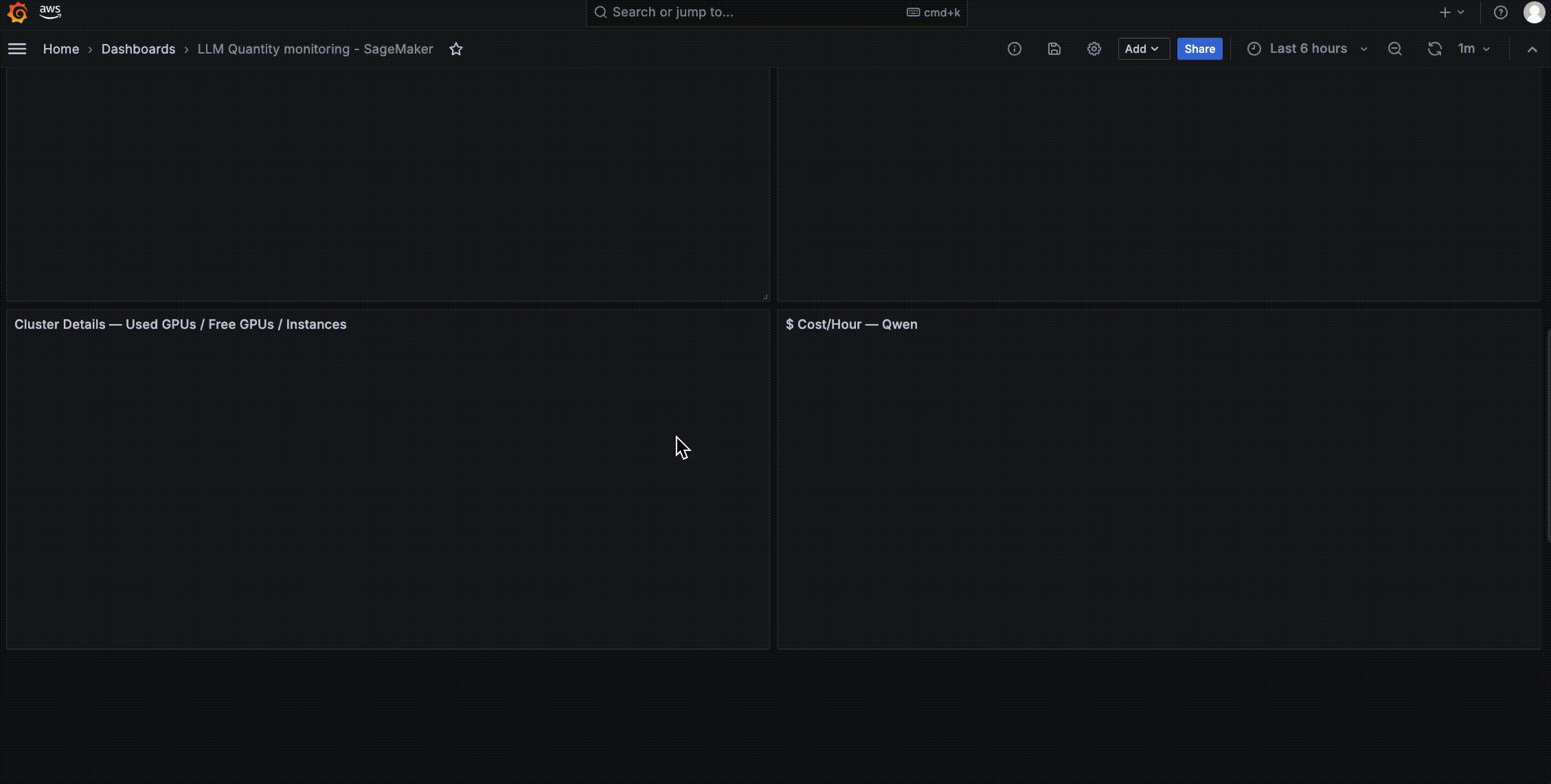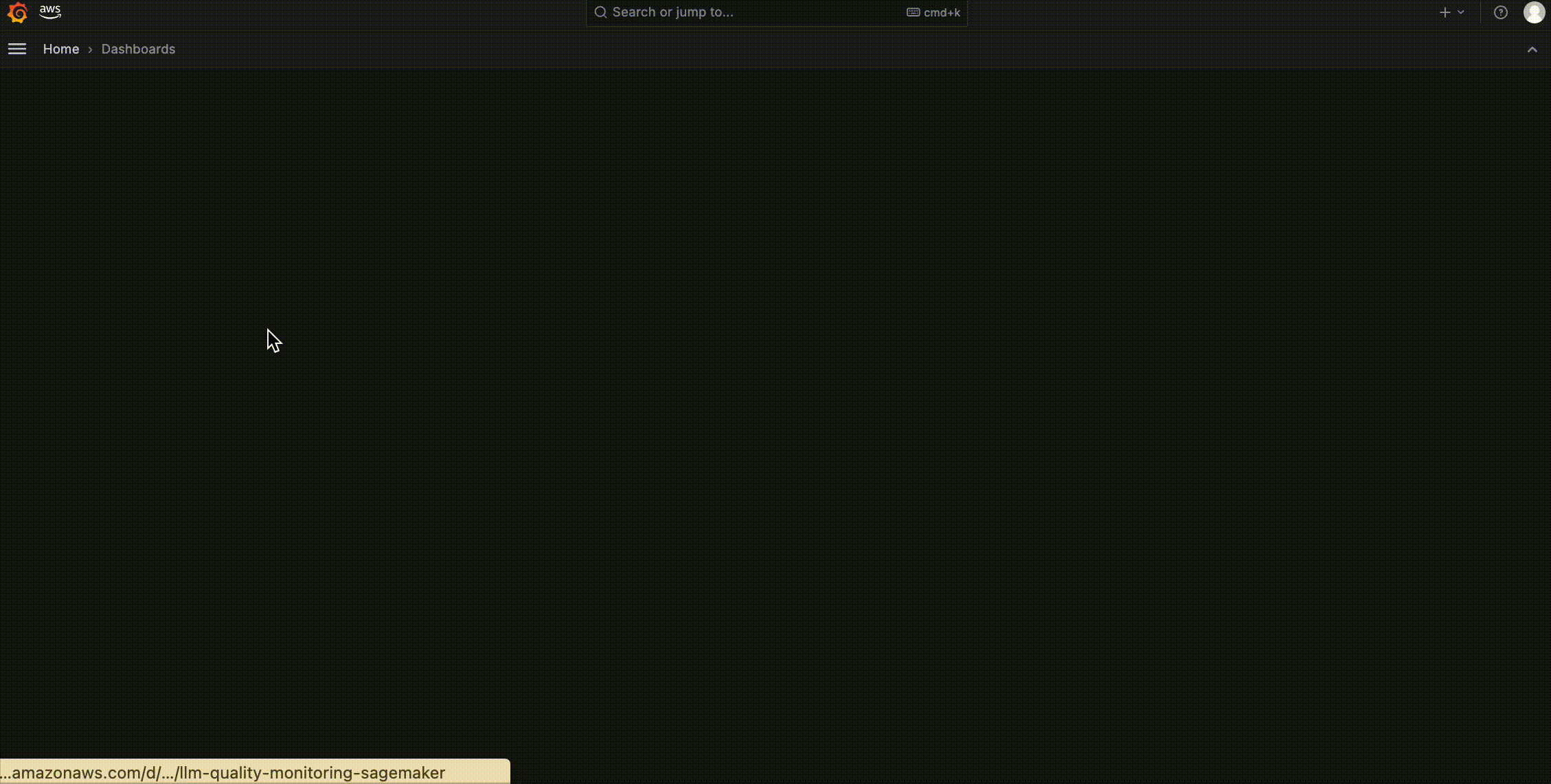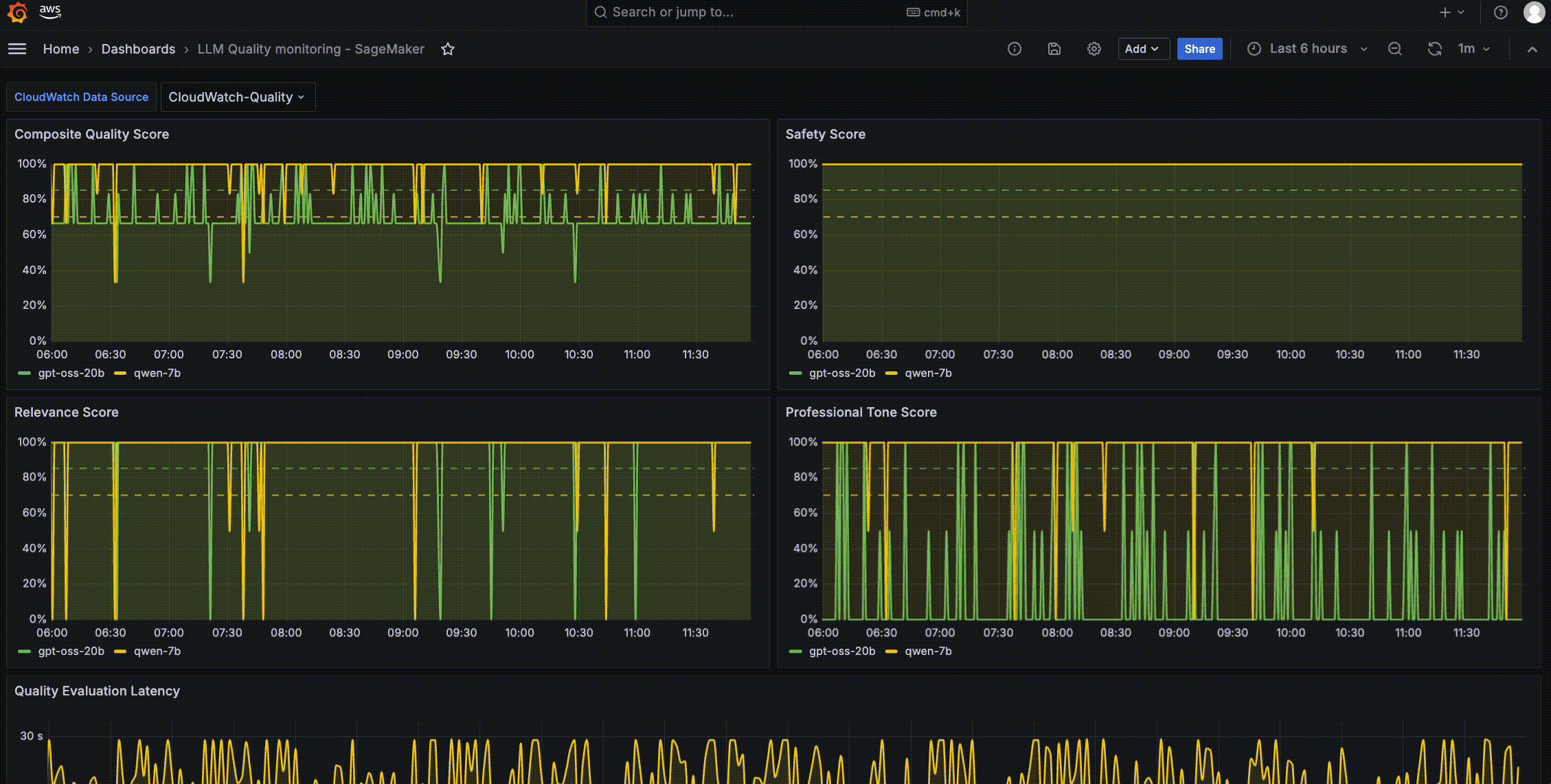
以下 Amazon Managed Grafana 控制面板示例输出展示了对 SageMaker AI 端点推理组件(例如 LLMs gpt-oss-20b 和 Qwen2.5-7B-Instruct)的质量监控。该示例控制面板跟踪四项质量评分,每项评分都以时间序列折线图显示,并带有可配置的告警阈值(以虚线显示,约为 85% 和 95%)。第一个面板显示综合质量评分(Composite Quality Score),这是一个结合多个质量维度的整体健康指标。该指标显示随时间变化的整体质量趋势,使团队能够直接识别持续性质量下降与间歇性质量下降,后者可能与特定提示词类型相关。
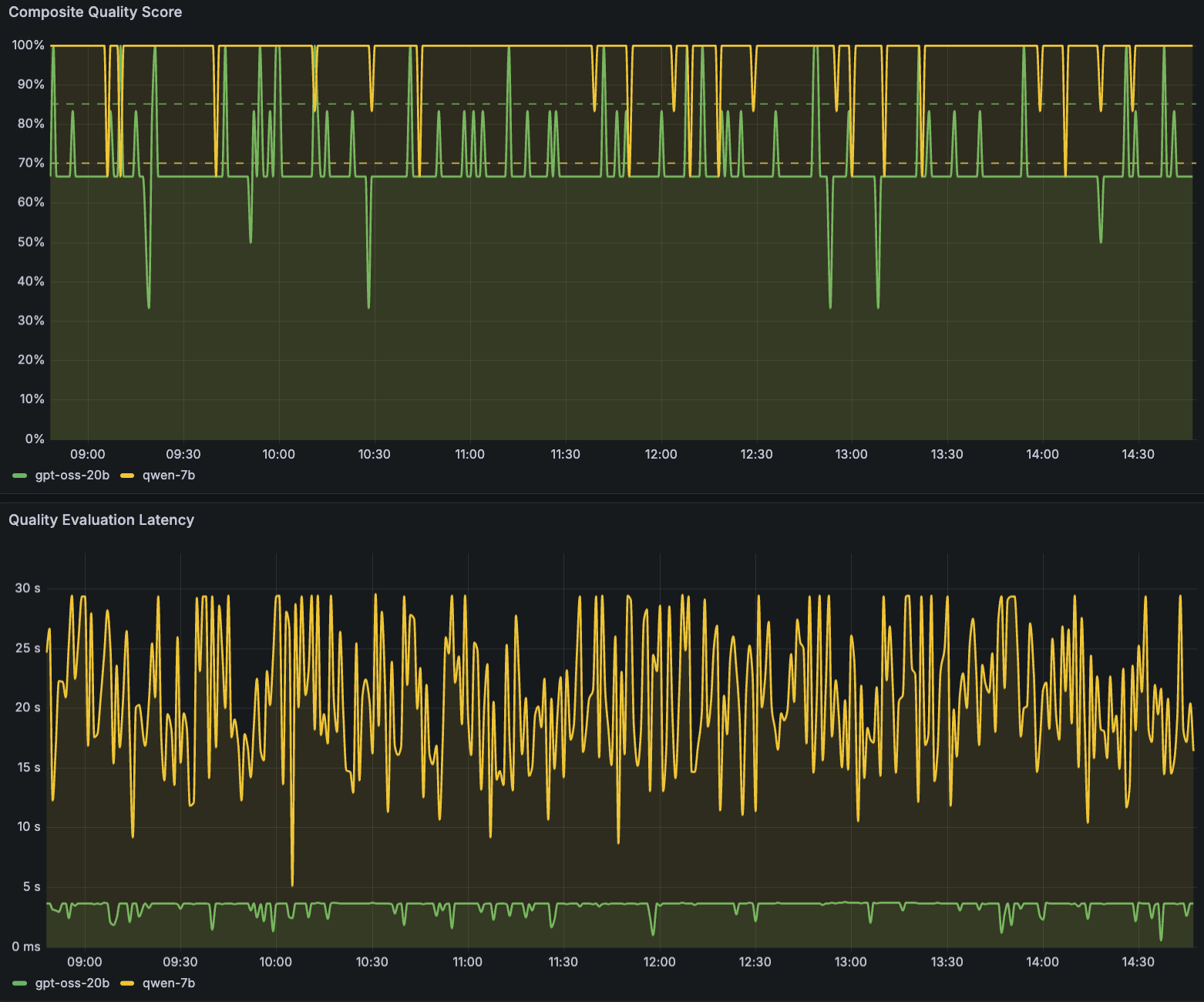
第二组面板跟踪特定的 LLM 响应质量指标:安全评分(Safety Score)、相关性评分(Relevance Score)和专业语气评分(Professional Tone Score)。安全评分监控对有害或不合规内容的检测。在控制面板输出中,该评分是四项指标中最稳定的,始终保持在目标阈值范围内,这表明两个模型都具备可靠的安全防护机制。相关性评分衡量 LLM 响应满足用户意图的程度,帮助团队识别可能对 LLM 理解能力构成挑战的提示词类别。专业语气评分评估输出是否保持适合部署场景的语气。
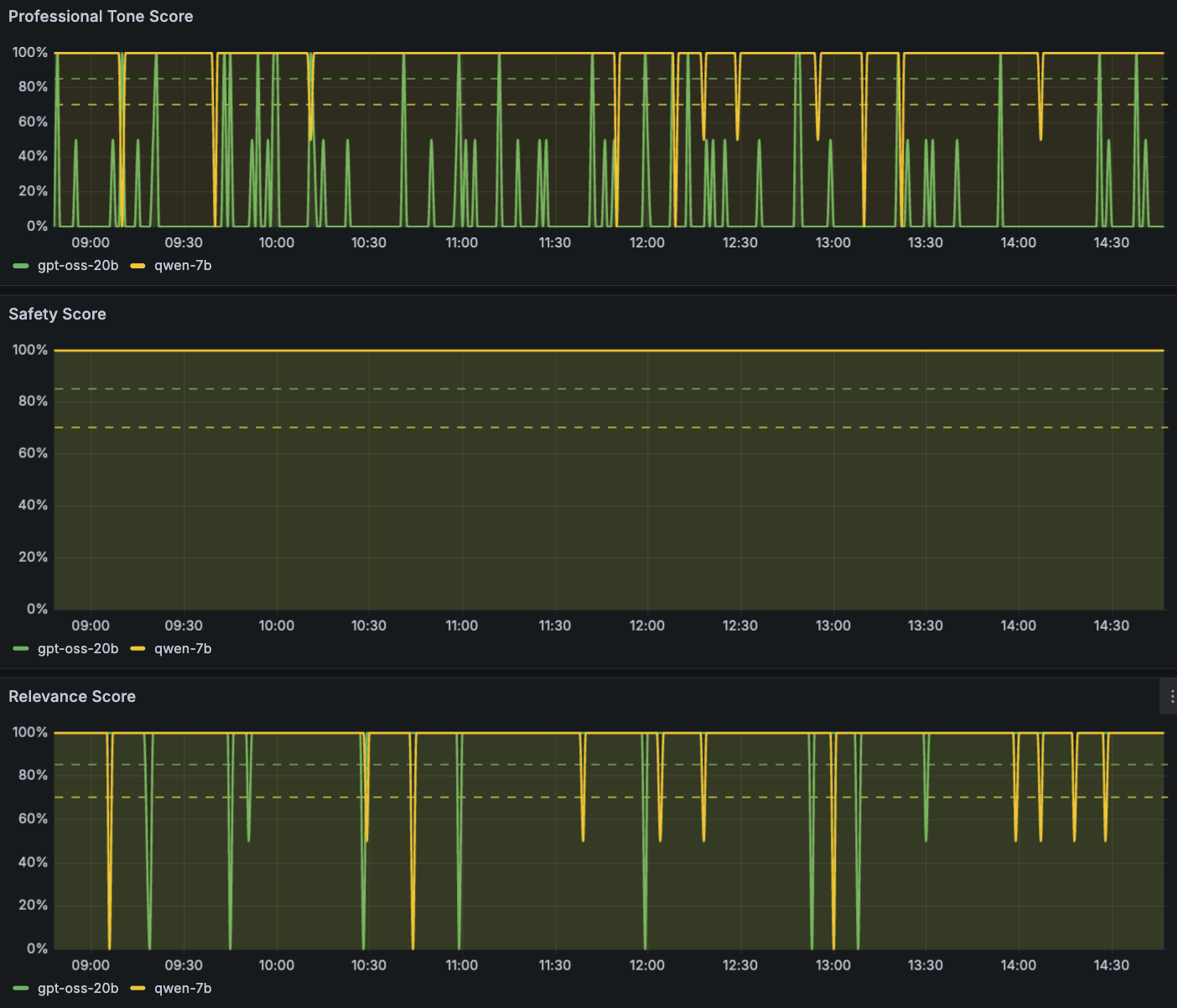
这些质量评分是使用评估指标计算得出的,例如采用可配置评估标准的 LLM-as-judge 模式。在这些示例中,我们使用通过 Amazon Bedrock 提供服务的 Anthropic Claude Sonnet 4.6 作为评估模型;根据标准 Amazon Bedrock 服务条款,该模型被允许用于 LLM-as-judge 用例。你可以替换为自己的评估系统,前提是你确认所选模型的条款允许评估其他模型的输出,验证已满足数据驻留要求,并将评估模型固定到某个特定版本,以便质量评分在一段时间内保持可比性。
一目了然地并排比较各个 LLM 的质量,识别哪个 LLM 更稳定、哪个质量维度是主要风险驱动因素,以及质量问题是间歇性的(表明对特定提示类型敏感)还是持续性的(表明模型退化)。除可视化之外,还会通过 Grafana Alerting 自动部署基于阈值的告警规则,并按推理组件进行维度划分,以便按每个推理组件触发告警。当质量评分突破其配置的阈值时,你可以通过 Amazon Simple Notification Service(Amazon SNS)接收这些通知,从而实现快速的 SRE 分诊。现代 SRE 团队会使用其现有的自动化分诊流程,例如将这些告警与 Slack、PagerDuty 或 OpsGenie 集成,通过自动关联日志、分类告警严重性并优先处理 i,将响应时间缩短到数秒。
以下 Grafana Alerting 仪表板示例输出显示了基于阈值的告警规则按每个推理组件触发,并将通知路由到已配置的渠道,以便 SRE 立即分诊。
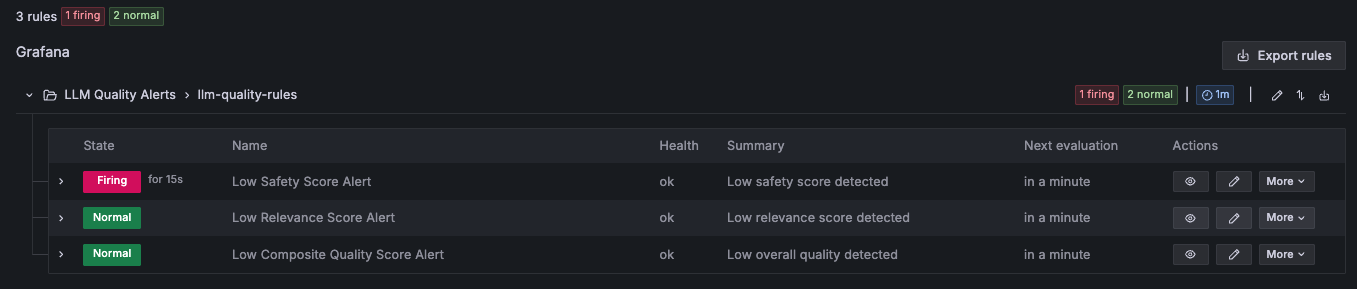
该视图为治理团队和产品团队提供了做出有关工程调整、补救措施、根因分析、模型替换或其他优化决策所需的证据。要在您的环境中设置此仪表板并进一步了解质量指标,请参阅 AWS samples GitHub repository notebook。
结论
生产环境中 LLM 推理栈的可观测性所需的不仅仅是跟踪正常运行时间和错误率。正如本文所展示的,全面的策略必须涵盖两个相辅相成的维度:数量和质量。数量涵盖基础设施的运行健康状况,包括 GPU 利用率、成本归因、扩缩容行为和请求吞吐量。质量涵盖模型的持续表现,包括响应相关性、安全合规性、事实准确性和专业语气。
通过结合 Amazon SageMaker AI 端点增强指标、Amazon CloudWatch 和 Amazon Managed Grafana,你可以在无需自定义埋点的情况下构建统一的可观测性层。增强指标可在共享基础设施上提供按模型、按 GPU 细分的粒度。CloudWatch 为运营信号和质量信号提供统一的指标存储。Grafana 将这些内容汇聚到仪表板中,服务于不同的利益相关方:负责监控资源饱和度和扩缩容的 SRE、跟踪安全与合规阈值的治理团队,以及并排比较模型质量的产品负责人。
要开始使用,请查看 AWS samples GitHub 仓库,其中包含用于配置增强指标、发布自定义质量指标和告警,以及设置本文所示 Grafana 仪表板的示例笔记本。
关于作者


