中文内容
如果你正在 AWS GPU 实例上反复部署大型语言模型(LLM),你可能已经注意到,要加载到 GPU 高带宽内存(HBM)中的模型越大,等待 GPU 准备好进行推理的痛苦时间就越长。随着模型增长到数千亿参数,GPU 环境规模也变得越来越大,模型加载时间会对端到端的首个 token 生成时间(TTFT)产生负面影响。本文探讨 Amazon FSx for Lustre 与 NVIDIA GPUDirect Storage(GDS)结合,再加上一些巧妙规划,如何从根本上改变冷启动 TTFT 的计算方式。它可以在每次模型启动时,将数分钟无产出的加载时间缩短到数秒。既然谈到优化,本文还将介绍最近发布的 TurboQuant KV cache 在大幅增加上下文窗口大小方面的影响。
背景:AWS 上的 NVIDIA Blackwell 架构
AWS 最近推出了由 NVIDIA Blackwell 架构提供支持的 Amazon EC2 P6e 和 P6 实例系列(观看发布公告)。旗舰级 P6e UltraServer 将 72 个 NVIDIA Blackwell GPU 集成到单个 NVLink 域中,具备 130 TB/s 的双向分割带宽、13.4 TB 的 HBM3e,以及 360 petaflops 的 FP8 计算能力(FP4 为 720 petaflops)。这些 UltraServer 通常用于万亿级参数规模前沿模型的大规模分布式训练。
在本文中,我们重点关注如何改善单个 P6 或 P5en 实例的冷启动 TTFT。具体而言,我们将介绍如何尽快将正确格式的模型权重加载到 HBM 内存中。对于包含多个节点的 UltraClusters,同样的过程会在集群中的所有节点上并行执行。UltraServer 中的每个节点都会从共享的 FSx for Lustre 文件系统独立加载模型,利用 FSx for Lustre 可提供的支持 GDS 的大规模可扩展吞吐能力。
模型加载瓶颈
首先,考虑 GPUDirect Storage 与基于 CPU 的模型加载之间的基本差异。传统的基于 CPU 的模型加载(左)会通过 CPU 内存流式传输检查点,并通过 PCIe 将权重依次复制到每个 GPU。分片式 GPUDirect Storage 加载(右)会在 Amazon FSx for Lustre 上预先将检查点按张量并行 rank 进行拆分,所有八个 GPU 通过 EFA 并行直接将各自的分片读取到 HBM 中,完全绕过 CPU,如图 1 所示。
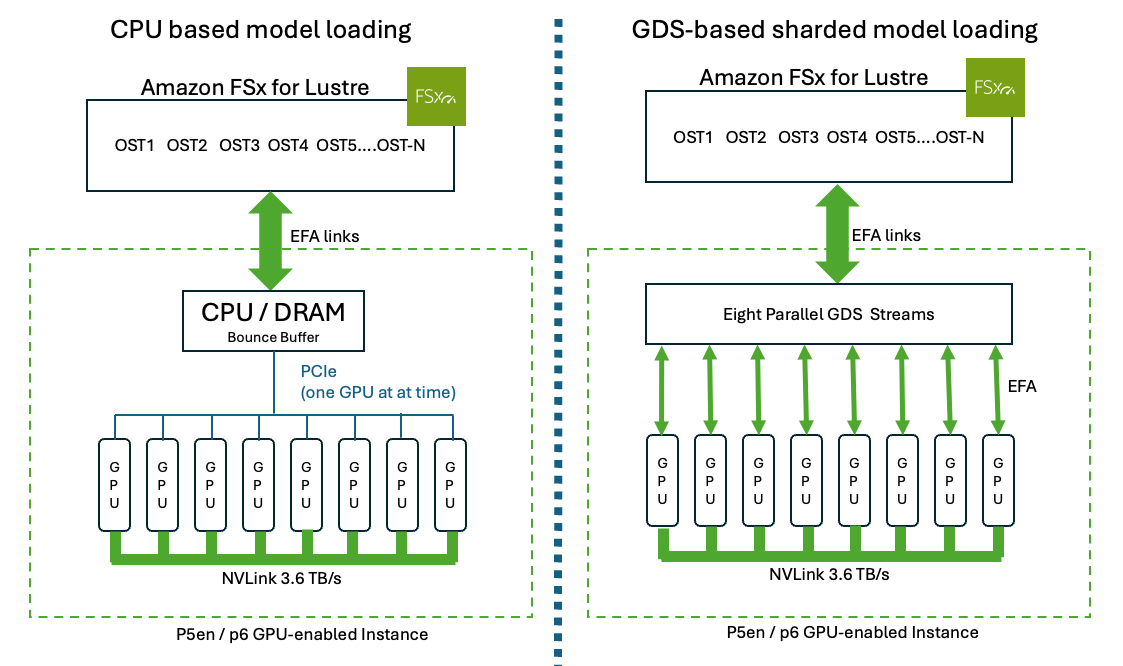
图 1:8-GPU 实例上的基于 CPU 的模型加载与分片式 GPUDirect Storage 加载对比。
以 Llama 3.1 405B 这样的 4050 亿参数模型为例,其 BF16 格式的检查点数据大约为 800 GB。传统的模型加载路径如下:
- 从存储中读取已保存检查点的模型文件到 CPU 系统内存
- 反序列化权重(torch.load 或 safetensors 解析)
- 可选地在 CPU 上进行量化(BF16 → FP8 或 INT4)——这会降低 HBM 需求
- 通过 PCIe 将权重从 CPU 内存逐一复制到每个 GPU。
这一流水线在很大程度上受限于单线程、顺序执行且受 CPU 约束。在没有 GDS 的典型部署中,带有 CPU 端量化的单线程模型加载 Llama 3.1 405B 需要 10–20 分钟。即使使用预分片的检查点,也仍然需要数分钟。在这整个过程中,你的 GPU(整个技术栈中最昂贵的资源)处于空闲状态,从而增加了从冷启动到首个 token 的时间。
值得注意的是,vLLM 等服务框架的近期版本已在模型加载方面取得了显著改进。vLLM V1 引擎(自 vLLM 0.19 起为默认引擎)引入了跨 GPU 的并行权重加载,与早期版本相比显著缩短了加载时间。然而,即使有这些改进,数据仍然会流经 CPU 内存和 PCIe 总线。GDS 则完全消除了这一瓶颈。
对于推理服务而言,这不仅仅是不便。较长的模型加载时间会直接影响:
- 冷启动延迟——新实例在模型加载完成前无法处理流量
- 自动扩缩容响应能力——扩缩容事件会延迟数分钟,而不是数秒
- 故障恢复——如果一个服务实例发生故障,替代容量需要数分钟才能上线
- 成本效率——加载期间消耗的 GPU 小时,是未用于处理请求的 GPU 小时
直接路径:FSx for Lustre 与 GPUDirect Storage
Amazon FSx for Lustre 是一种完全托管的高性能并行文件系统,专为计算密集型工作负载而设计。结合对 NVIDIA GPUDirect Storage 的支持后,FSx for Lustre 可建立多条直接通往 GPU 内存的数据路径,完全绕过 CPU 和系统内存。
这一集成依赖于两项关键技术的协同工作:
- Amazon Elastic Fabric Adapter (EFA) 使用 AWS Scalable Reliable Datagram (SRD) 协议来绕过操作系统开销。P5en 实例配备 16 个 EFA 接口,每个接口 200 Gbps,可提供 3,200 Gbps(400 GB/s)的总网络带宽。FSx for Lustre 可以使用其中八个或更多 EFA 接口,实现从存储到 GPU 的直接数据传输。
- NVIDIA GPUDirect Storage(GDS)支持从网络接口直接到 GPU HBM 的 DMA 传输,消除了造成传统瓶颈的 CPU 内存中转缓冲区。
其结果是,相比传统的基于 TCP 的存储访问,吞吐量显著提升。但原始吞吐量只是其中一部分。真正的突破来自这条直接路径在架构上所支持的能力:在使用分片并行模型加载时绕过 CPU。
在我们的测试配置中,我们使用一个 Persistent_2 EFA 文件系统,带宽为 1000 MBps/TiB,包含 20 个对象存储目标(OST)(容量 96 TiB),可提供约 94 GiB/s 的文件系统吞吐量。吞吐量会随文件系统容量线性扩展。更大的文件系统意味着更多 OST 和更多并行 I/O 路径。有关构建高吞吐量 FSx for Lustre 文件系统的演示,请参阅早前的博客《Build and deploy a 1 TB/s file system in under an hour》。设置命令请参见下一节中的 Stage 0。
要为 P5en 客户端配置支持 GDS 的 FSx for Lustre 访问,请按照《FSx for Lustre User Guide》中“Configuring EFA clients”的步骤操作。AWS 提供的配置脚本(setup.sh –optimized-for-gds)会自动检测您的实例类型,使用具备 NUMA 感知 CPU 分区的正确 EFA 接口进行配置,并创建 systemd 服务,以便该配置在重启后仍然保留。默认情况下,P5en 仅将其 8 个 EFA 接口用于 FSx for Lustre,这提供了从存储到每个 GPU 的 HBM 的直接 GDS 数据路径。
P5en(8x H200)上的分片并行加载
为说明分片加载方法,我们将使用 P5en 实例(p5en.48xlarge)——8 个 NVIDIA H200 GPU,每个配备 141 GB HBM3e,并通过 NVSwitch 连接,二等分带宽为 3.6 TB/s。P5en 支持 GDS,并具有与 P6-B200 相同的 3,200 Gbps SRD EFA 网络,因此是展示这一模式的理想平台。由于每个节点具有相同的单实例网络带宽,存储读取阶段的性能特征在 P6 节点上也将完全相同。
对于任何足够大的模型(例如 FP8 格式下约 400 GB 的 Llama 3.1 405B),权重都无法放入单个 GPU 的 HBM 中(H200 上为 141 GB)。因此需要张量并行,将模型拆分到多个 GPU 上。这意味着在推理过程中,GPU 之间需要通过 NVLink 进行低延迟通信(用于注意力层和多层感知机(MLP)层之后的 all-reduce 操作),这也是为什么像 P5en 和 P6 这类通过 NVSwitch 连接的实例对于服务这些模型至关重要。该方法分为四个阶段:虽然我们使用 Llama 3.1 405B 作为参考模型,但这种模式适用于任何支持张量并行分片的模型,包括 Mixtral、DeepSeek 和自定义架构。关键要求是服务框架能够将模型拆分为每个 GPU 的分片。
阶段 0:预置基础设施。在加载任何模型之前,你需要在同一个 Amazon Virtual Private Cloud(Amazon VPC)和可用区(AZ)中准备两项内容:一个启用了 EFA 的 FSx for Lustre 文件系统,以及一个配置为支持 GPUDirect Storage 的 P5en(或 P6)GPU 实例。我们在配套的 aws-samples 代码库中提供了 AWS CloudFormation 模板和设置脚本,用于自动完成下一节所述的基础设施预置和 GDS 配置。
FSx for Lustre 文件系统应为启用了 EFA、吞吐量设置为 1000 MBps/TiB 的 Persistent_2 SSD 部署,如前面的“A direct path”部分所述。文件系统容量决定了你的聚合读取吞吐量。容量越大,意味着 OST 越多,并行 I/O 路径也越多。
P5en 实例需要配置其所有 EFA 接口,安装 EFA 驱动程序,构建并加载 NVIDIA GDS nvidia-fs.ko 内核模块,配置具备 NUMA 感知能力的 Lustre 客户端网络以获得最佳吞吐量,并部署 GDS 运行时配置(cufile.json)。这涉及多个步骤:构建 NVIDIA nvidia-fs.ko 模块,根据实例的 NUMA 拓扑将 EFA 接口与 CPU 分区对齐,以及调优 Lustre 客户端参数。请按照 FSx for Lustre User Guide 中的 Configuring EFA clients 指南完成完整的设置流程。
基础设施准备就绪后,在输出目录上设置 Lustre 条带化,以确保来自多个 GPU 的并发 GDS 读取分布到所有 OST 上:
# Stripe across all OSTs with 16 MB stripe size (matches optimal GDS block size)
mkdir -p /fsx/model_shards/Llama-3.1-405B-FP8-8way
lfs setstripe -c -1 -S 16M /fsx/model_shards/Llama-3.1-405B-FP8-8way阶段 1:对模型权重进行预分片和预量化。离线使用 vLLM 将模型拆分为 8 个张量并行分片,并进行 FP8 量化,然后将它们保存到 FSx for Lustre。源检查点为 BF16 格式(HuggingFace 上 Llama 3.1 的标准格式)。预分片步骤会将权重量化为 FP8,从而将需要通过 GDS 加载的数据量减半:
python save_sharded_state.py \
--model /fsx/models/Llama-3.1-405B \
--quantization fp8 \
--tensor-parallel-size 8 \
--output /fsx/model_shards/Llama-3.1-405B-FP8-8way这会生成 8 个具备张量并行(TP)感知能力的分片,其中每个分片都恰好包含该 GPU 推理所需的权重切片。注意力头和 MLP 列会在各 GPU 之间正确拆分。这些分片已预先量化为 FP8,将总检查点大小从约 800 GB 减少到约 400 GB。输出目录将如下所示:
/fsx/model_shards/Llama-3.1-405B-FP8-8way/
├── model-rank-0-part-0.safetensors # ~51 GB — GPU 0's slices
├── model-rank-1-part-0.safetensors # ~51 GB — GPU 1's slices
├── ...
├── model-rank-7-part-0.safetensors # ~51 GB — GPU 7's slices
├── config.json
├── tokenizer.json
└── tokenizer_config.json每当你更新基础模型检查点时,例如在微调后或切换到新的模型版本后,都需要重复此预分片步骤。由于它是离线运行的,并且分片后的输出会在之后每次加载时重复使用,因此摊销成本很低。
如果你能控制训练流水线,就可以完全移除这一步。Megatron-LM 和 NeMo 等框架可以直接以服务栈所需的张量并行布局和精度保存检查点。例如,以 FP8 safetensors 格式保存的 8 路 TP 分片。当训练以服务格式保存时,检查点即可用于 GDS 并行加载,无需任何后处理。请注意,Megatron-LM 默认以 torch_dist 格式保存检查点,在这些分片可供基于 safetensors 的加载器使用之前,需要通过 Megatron Bridge 进行转换——这是一次性转换步骤,只会增加极少的开销。
我们在本文中选择 FP8,是因为它是 H200 和 B200 上具有原生 Tensor Core 支持的一等数据类型,在 vLLM 中只需一个标志(–quantization fp8),并且在 Llama 类模型上几乎没有准确率损失。更激进的 4 位权重量化方法(AWQ、GPTQ 和 HQQ)结合 vLLM 中优化的 W4A16 服务内核,可以将检查点大小再减少 2 倍,并在带宽受限的工作负载上提升生成吞吐量(在 H100/H200 上小批量大小时相比 FP8 提升 2–3 倍)。AWQ 和 GPTQ 需要对代表性数据进行一次简短的校准。HQQ 不需要数据。本文中的 GDS 加载模式与量化方法无关。无论你的服务框架支持哪种格式,从 FSx for Lustre 进行并行分片加载都以相同方式适用。一个 4 位 405B 检查点的加载时间大约是下一节报告的 FP8 结果的一半
FP8 量化将检查点大小减半,从而缩短加载时间,但权重量化并不是唯一可用的手段。TurboQuant(Google Research,ICLR 2026)及其底层 PolarQuant 方法等新兴技术瞄准的是 Key-Value(KV)缓存,即推理过程中会随上下文长度增长而增长的内存。根据作者所述,TurboQuant 可将 KV 缓存压缩到每个值约 3 bit(减少 6 倍),在 NVIDIA H100 GPU 上的注意力计算速度最高提升 8 倍,并且准确率零损失,同时无需微调。虽然这些方法不会直接减少检查点大小或模型加载时间,但它们能显著降低推理期间的 HBM 消耗,从而释放 GPU 内存,用于更长的上下文窗口或更大的批量大小。结合本文使用的 FP8 权重量化,KV 缓存压缩进一步降低了整体 HBM 需求。这可以帮助你进行服务
阶段 2:并行 GDS 读取。在加载时,全部 8 个 GPU 会同时通过 GDS 从 FSx for Lustre 将分配给自己的分片直接读取到 GPU HBM 中。由于这些分片已预先量化为 FP8,需要读取的数据总量约为 400 GB,即每个 GPU 约 50 GB。GDS 完全绕过 CPU 内存,因此不会通过主机发生串行化。全部 8 个读取操作并行进行。
对于 GDS 读取路径,我们使用 fastsafetensors,这是一个开源库,可使用 NVIDIA cuFile(GDS API)将 safetensors 文件直接读取到 GPU 内存中,并在不进行任何 CPU 端反序列化的情况下重建 PyTorch 张量。每个 GPU 打开自己的分片文件,执行一次大型 GDS 读取到 GPU 缓冲区,然后使用 safetensors 头部元数据从缓冲区中提取所有张量。张量提取步骤耗时不到一毫秒,因为它只是对已加载到 GPU 缓冲区中的数据进行指针运算。
在加载模型之前,请确认 GDS 内核模块已加载,并且 Lustre 客户端已为 EFA 完成配置:
# Verify the GDS kernel module is loaded
lsmod | grep nvidia_fs
# Verify EFA interfaces are active for Lustre
sudo lnetctl net show | grep -c "nid:.*@efa"
# Should show 16 (one per EFA interface configured for Lustre — not all instance NICs)
# On single-node deployments, the setup script configures all 16 EFA interfaces for Lustre.
# In UltraCluster multi-node configurations, you may configure 8 interfaces for FSx
# and reserve the remaining 8 for inter-node NCCL collective traffic.如果 nvidia_fs 未加载,GDS 读取将静默回退到 CPU 弹性缓冲区路径。你仍会得到正确结果,但无法获得性能收益。使用 sudo modprobe nvidia_fs 加载该模块。使用 fastsafetensors,每个 GPU 会并行加载其分片:
from fastsafetensors import SafeTensorsFileLoader
# Each GPU loads its own shard via GDS
loader = SafeTensorsFileLoader(pg=None, device=f"cuda:{rank}", nogds=False)
loader.add_filenames({0: [f"/fsx/model_shards/Llama-3.1-405B-FP8-8way/model-rank-{rank}-part-0.safetensors"]})
fbuf = loader.copy_files_to_device() # GDS read: storage → GPU HBM directly
# Extract tensors — sub-millisecond, just pointer math into the GPU buffer
tensors = {name: fbuf.get_tensor(name) for name in loader.get_keys()}阶段 3:验证并提供服务。张量通过 GDS 加载到 GPU HBM 后,所有推理计算都完全在 GPU 内存中运行。文件系统仅在初始加载期间参与。第 2 阶段中的 tensors 字典包含此 rank 的每个权重,这些权重已位于正确的 GPU 设备上,并采用正确的张量并行布局。没有使用 CPU 内存,也没有发生反序列化。权重直接从 FSx for Lustre 存储进入 GPU HBM。
这些张量可供任何接受预加载权重字典的张量并行推理引擎直接使用。集成点因框架而异:vLLM、TensorRT-LLM 和 SGLang 各自都有内部 API,用于将权重注入其支持 TP 的模型图中。随着这些框架原生采用支持 GDS 的权重加载(fastsafetensors 正是由 Foundation Model Stack 团队为这种集成而构建的),第 2 阶段所示的完整 GDS 路径将成为单命令操作。
对于当前的生产服务,vLLM 可以从 FSx for Lustre 加载相同的预分片检查点:
vllm serve /fsx/model_shards/Llama-3.1-405B-FP8-8way \
--load-format sharded_state \
--quantization fp8 \
--tensor-parallel-size 8vLLM 内置的权重加载器使用标准的基于 CPU 的读取路径,而不是 GDS。预分片格式仍然消除了标准检查点加载中占主导地位的反序列化和按 GPU 拆分权重开销,将 Llama 3.1 405B 的加载时间从约 18 分钟缩短到约 2 分钟(见下一节中的性能表)。第 2 阶段的 GDS 并行路径进一步提升了这一点,将约 2 分钟缩短到约 6 秒。
性能差异
这些是实测结果。以下表格比较了在 P5en 实例(8x H200)上,使用 96 TiB Persistent_2 EFA 文件系统(20 个 OST,文件系统吞吐量约 94 GiB/s)时,不同加载方法的模型加载时间。
实测:Llama 3.1 70B Instruct(8 路 TP,冷缓存)
Loading Method Total Load Time Speedup Standard vLLM load (BF16 checkpoint, FP8 quantize-at-load, no GDS) ~3 min 1x GDS parallel load — BF16 shards (141 GB) 2.17 s ~83x GDS parallel load — FP8 shards (72 GB) 1.28 s ~141xGDS 加载时间按每个 rank 计算(全部 8 个 GPU 并行加载),使用 fastsafetensors,它通过 GDS 将 safetensors 文件直接读入 GPU 内存并重构张量。没有 CPU 中转缓冲区,也没有反序列化开销。每个 rank 加载自己的分片,并在一秒多一点的时间内将全部 1,124 个张量准备到正确的 GPU 设备上。基线时间除了权重加载外,还包括 vLLM 引擎初始化和预热,因此 GDS 行具体表示从存储到 GPU 的传输时间。
实测:Llama 3.1 405B Instruct(8 路 TP,冷缓存)
Loading Method Total Load Time Speedup Standard vLLM load (BF16 checkpoint, FP8 quantize-at-load, no GDS) ~18 min 1x GDS parallel load — BF16 shards (812 GB) 10.4 s ~104x GDS parallel load — FP8 shards (408 GB) 6.4 s ~169x这些结果是在一个 96 TiB 文件系统(20 个 OST)上测得的。由于 GDS 吞吐量会随 OST 数量线性扩展,更大的文件系统会按比例缩短加载时间。例如,一个拥有 57 个 OST 的 342 TiB 文件系统有可能将 FP8 加载时间降至 3 秒以内。扩展计算如下:94 GiB/s × 57/20 OST ≈ 268 GiB/s 的理论上限。保守估计,在计入每个 OST 的开销后约为 190 GiB/s,这意味着 408 GB ÷ 190 GiB/s ≈ 2.0 秒。在 P6 节点上的加载性能将相同,因为它具有相同的每实例 EFA 带宽。这种模式对大到需要跨多个 GPU 进行张量并行的模型影响最大。这正是并行读取优势发挥作用的地方。对于能够放入单个 GPU 的较小模型,传统的加载瓶颈在于 CPU(反序列化、量化和串行 PCIe 传输),而带有并行读取的 GDS 所能提供的优势较少。
- 无 CPU 弹跳缓冲区——GDS 直接读取到 GPU HBM
- 无串行反序列化——预先分片的模型权重已可按原样加载
- 无 CPU 量化——已离线预量化,而非在加载时量化
- 无需顺序加载 GPU——所有 8 块 GPU 并行读取
- 无需 all-gather——支持 TP 的分片意味着每块 GPU 已经拥有其所需的准确权重
但快速加载只是其中一部分。FP8 量化不仅缩短了加载时间,还将模型权重的 HBM 占用减半,从而释放内存用于 KV cache 和服务。结合 TurboQuant 的 KV cache 压缩(每个值 3–4 位),用于推理的可用 GPU 内存显著增加:
P5en (8x H200) P6 node (8x B200) HBM per GPU 141 GB (HBM3e) 192 GB (HBM3e) Total HBM 1,128 GB 1,536 GB 405B FP8 weights per GPU ~51 GB ~51 GB Free HBM per GPU for KV cache ~85 GB ~136 GB FP16 KV cache context capacity ~82K tokens ~131K tokens With TurboQuant K4/V4 (3.76x) ~310K tokens ~495K tokens With TurboQuant K4/V3 (~5x) ~412K tokens ~660K tokensFP8 权重与 TurboQuant KV cache 压缩的结合意味着,你可以在单个 P5en 上以超过 400K token 的上下文窗口服务 Llama 3.1 405B,或在 P6 节点上以接近 500K token 的上下文窗口服务。这相当于单次请求从处理几份文档提升到处理一整本书。
还值得注意的是,FSx for Lustre 文件系统并不是单一用途的基础设施。用于加速模型加载的同一个文件系统,也可以作为团队内训练数据、检查点、数据集和模型工件的共享存储。通过减少模型加载期间的 GPU 空闲时间,可以提高模型测试和评估的迭代速度。将新模型变体的加载时间从数分钟缩短到数秒,意味着每天可以进行更多实验。有关当前费率,请参阅 FSx for Lustre 定价。
与服务框架集成
这种模式适用于你可能已经在使用的推理服务框架。
TensorRT-LLM 原生支持张量并行检查点加载。你可以使用 8 路张量并行来转换并构建引擎,并通过 mpirun 在所有 GPU 上启动。当底层文件系统支持 GDS 时,TensorRT-LLM 可以自动利用从存储到 GPU 的直接路径。
vLLM 支持跨 GPU 的张量并行,并可配置为使用 –tensor-parallel-size 8 来服务模型。虽然 vLLM 的默认加载路径基于 CPU,但预分片检查点方法结合启用 GDS 的存储,可在文件系统层面提供 I/O 加速。
摘要
通过结合 Amazon FSx for Lustre、NVIDIA GPUDirect Storage 以及预分片、预量化的模型检查点,我们将 Llama 3.1 405B 的加载时间从未使用 GDS 时的 10–20 分钟缩短到在 96 TiB 文件系统上使用 GDS 时的 6 秒。通过扩展到更大的文件系统,还可以获得进一步提升。此外,通过应用 TurboQuant KV 缓存压缩(每个值 3–4 位),Llama 3.1 405B 的可用上下文窗口在 P5en 上从约 82K tokens 增加到超过 400K tokens,或在 P6 上从约 131K tokens 增加到约 660K tokens。这是在相同硬件上实现的 5 倍提升。
这种方法的主要优势:
- 冷启动速度大幅提升——新的推理实例可在数秒内就绪,而不是数分钟
- 改进的自动扩缩容——扩缩容事件能够近乎实时地响应需求峰值
- 更低的每 token 成本——GPU 将时间用于提供推理服务,而不是等待权重加载
- 更快的故障恢复——故障实例可在数秒内被替换并开始处理流量
- 随集群扩展——UltraCluster 中的每个节点都从同一个共享文件系统并行独立加载
- 大幅增加上下文窗口——TurboQuant KV 缓存压缩使同一硬件上的上下文长度增加 5 倍
该模式目前可在配备 FSx for Lustre Persistent_2 EFA 文件系统的 P5en 和 P6 实例上运行,并使用 vLLM 和 TensorRT-LLM 等标准服务框架。立即开始更快地加载更大的模型。
关于作者

