中文内容
待翻译official company source英文原文2026-06-03
Improve your agent’s tool-calling accuracy with SFT and DPO on Amazon SageMaker AI
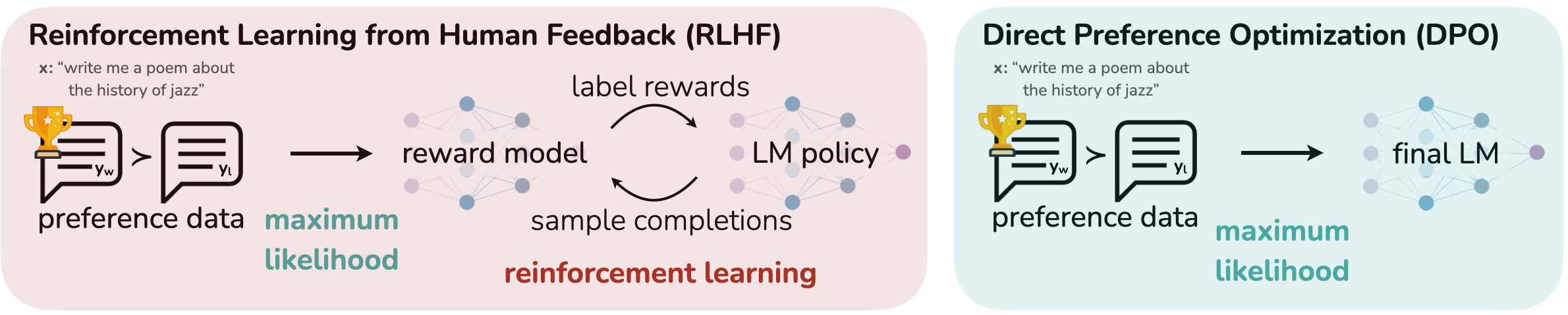



In this post, you learn how to use Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) together to improve the tool-calling accuracy of a small language model (SLM). The example uses Amazon SageMaker AI training jobs, so you can focus on training code instead of managing your own training infrastructure. You also learn how to evaluate tool-calling accuracy and compare a base model to several fine-tuned variants, so you can make data-driven decisions about model quality.