中文内容
随着 AI 模型日益复杂,且在加州 AB-2013 和欧盟 AI Act 等框架下监管审查不断加强,软件团队面临的挑战已不只是交付优秀代码:他们需要在模型发布前生成全面、可审计的模型文档。
模型卡描述模型的工作方式、预期用途和许可证、训练数据、性能以及局限性。它们促进透明度和问责制,使下游用户——客户、监管机构和受影响的社区——在选择和部署 AI 时能够做出知情决策。其受众不止开发者:政策制定者、采购团队和风险评估人员都依赖模型卡来评估适用性,并比较不同供应商的模型。
在实践中,手动创建模型卡繁琐且缓慢。文档往往落后于开发进度,元数据到发布时常常已经过时。随着模型变得更复杂,格式不一致和缺少必填字段会造成不必要的审计风险,并减缓采用速度。NVIDIA model card generator(MCG)toolkit 可通过直接读取源数据,在一分钟内以 Model Card++ 格式自动化并标准化模型文档。
介绍 NVIDIA MCG toolkit
MCG toolkit 是一个容器化流水线,通过读取模型源代码来自动生成模型卡。它遵循模块化的“摄取 → 提取 → 渲染”流水线。中央编排器接收你的请求——可以是 URL 或上传文件——协调工作流,并返回一份完整的模型卡。每个阶段都作为独立服务运行,因此你可以更新或替换单个组件,而不影响流水线的其余部分。
MCG toolkit 的工作方式
该工具包提供交互式 UI,可接受 URL(GitHub、GitLab、HuggingFace 或任何公共网页)或上传文件(ZIP、PDF、DOCX 或 Markdown)。同时也提供 REST API,用于程序化集成。
随后,数据流经三个阶段:
- 输入 → 摄取。系统获取内容,并将其处理为文档块,按类型分类:文档、配置文件和代码。
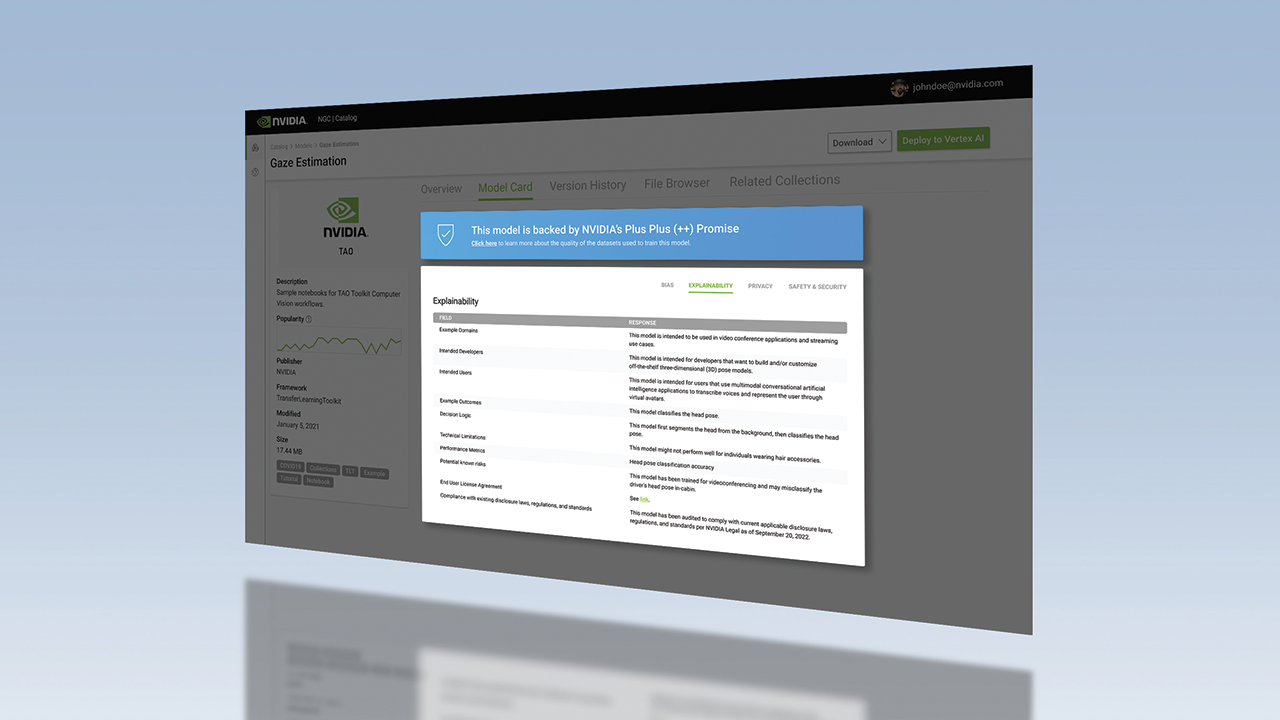
- 文档 → 提取。提取阶段将已摄取文档送入由 NVIDIA Inference Microservices(NIM)驱动的检索增强生成(RAG)流水线。NVIDIA Nemotron RAG 负责高精度嵌入(llama-nemotron-embed-1b-v2)和重排序(llama-nemotron-rerank-500m-v2),并针对代码、配置文件和文档分别使用检索器,以优先处理信号更强的来源。核心提取由 GPT-OSS-120B 执行,它读取检索到的段落,并应用专家策划的格式和内容指南——NVIDIA MC++ 模板以及字段级风格指南——以预期格式生成合规信息。验证步骤会在响应被接受前进行检查。输出为结构化 JSON。概览完成后,相同内容会流向子卡片阶段,生成四个 Model Card++ 子卡片:Bias、Explainability、Privac
- JSON → 渲染。结构化 JSON 使用可配置模板渲染为人类可读的 Markdown。你可以在界面中编辑内容,并在下载或与其他系统集成前重新渲染。最终产物是一份完整模型卡——包含概览和四个子卡片——可供审阅或发布。

为灵活性而设计
你不会被锁定在某一个模型、模板或标准中。该工具包可在三个维度上自定义:
1)模型:系统为语言模型、嵌入和重排序使用可配置端点。可指向不同的 NIM 或兼容 API,以匹配你的性能、成本或数据驻留要求,无论你是在较小模型上进行原型开发,还是扩展到生产环境。
2)模板:输出格式由 Markdown 模板驱动。组织可以针对 Model Card++、内部标准或新兴监管格式进行自定义,而无需修改提取逻辑。输出也符合 CycloneDX 标准。当出现新的披露要求时,你更新模板,而不是更新流水线。
3)指南:字段级指导——需要捕获什么、如何表述——来自可配置知识库。随着法规或领域需求演进,可更新指南而无需触碰核心代码。同一条流水线可服务于不同行业和合规制度。
在你需要的地方运行
该工具包以容器化服务形式交付,支持一条命令完成设置。编排器、摄取、提取和子卡片阶段各自作为独立容器运行,并包含基础设施(数据库和任务队列)。不存在专有云锁定:MCG 可在本地或你自己的云中运行,并支持 Kubernetes,帮助你在自有基础设施上启动。
性能结果
我们在公共模型仓库上对该工具包进行了标准化测试,以衡量完成率、生成时间和准确性。每个字段都根据源文档评分。准确性按正确字段数除以非占位字段数计算。下方表 1 显示结果。
对于大多数仓库,该工具包可在一分钟内生成完整模型卡(概览加四个子卡片)。总体完成率达到 91%(第三方基线),在标准化测试集上的准确性为 76%。完成率和准确性因模型和仓库而异;README 和配置文件更丰富的仓库会取得更高结果。
当存在支持性文档且代码库结构良好时,该工具包表现最佳,并会尽可能使用代码分析进行补充。当文档稀少或缺失时,填充的字段会减少;系统不会猜测,而是显示“未找到”或“信息不可用”,以标示需要人工审查的缺口。
我们还测试了完全移除文档时会发生什么。使用标准测试集中的相同仓库,我们删除所有 .pdf、.md 和 .txt 文件,并仅针对代码重新运行该工具包。在五个模型中,平均完成率从 91% 降至 61%;严格准确性仅按可验证字段衡量,从标准测试中的 76% 降至 28%,而标准测试只对已完成字段计算准确性。
61% 的完成率表明,该工具包仍能仅从代码、配置文件和仓库结构中提取有意义的信号;准确性下降反映了文档对正确填写这些字段有多大贡献。
关键在于,该工具包不会通过猜测来弥补。如果它无法有把握地填充字段,这些字段会显示为“未找到”或“信息不可用”,这使其既适合作为文档仍在编写团队的缺口发现工具,也适合作为文档已完整团队的生成工具。
早期采用者和行业合作伙伴
Oracle 是首批将 MCG Toolkit 集成到生产基础设施中的合作伙伴之一。作为其 OCI AI 产品的一部分(涵盖从 A10 到 GB200 NVL72 的 GPU 配置),Oracle 部署了 OCI container engine for Kubernetes 与 AI 产品的工具包组合,在由 Object Storage 支撑 NIM 模型的标准 VCN 架构内运行 MCG pod 和 NIM pod。其部署使用 Llama-3.3-Nemotron-Super-49B-v1 作为核心提取模型,并由 Nemotron RAG 处理嵌入和重排序。GPT-OSS-120B 模型托管并测试于配备 2xH100 卡的专用 AI 集群以及该模型的按需产品上。OCI 支持越来越强大的 GPU 基础设施,用于大规模 AI 训练和推理;对一致、可审计模型文档的需求也随之增长。OCI Dedicated AI Cluster(DAC)是一种私有、fu
开始使用
如果你希望成为早期采用者,请联系 Trustworthy AI 团队。我们很乐意讨论合作。
还没准备好使用全自动工具包?Trustworthy AI GitHub 仓库提供开源 Model Card++ 模板,以及面向蓝图、数据集、容器和系统的 AI 透明度卡,你现在就可以使用。
文档应与您交付的模型保持同步。无论你采用 MCG toolkit,还是从我们的开源模板开始,NVIDIA 的 Trustworthy AI 计划都致力于让这件事变得更容易。
标签