中文内容

概览
- 现代 AI 系统之所以强大,并不是因为它们复制了人类智能,而是因为它们以人类智能为前提,延展了人类认知和语言中已有的结构。
- 这一视角有助于解释 AI 的非凡能力及其反复出现的边界,包括幻觉和推理失效。
- 这项研究认为,AI 安全是一个系统层面的挑战,应将注意力从“失控 AI”的叙事转向利用工程与治理手段。
- 将 AI 理解为人类智能的延展,而不是其替代品,为构建可信 AI 系统提供了一条更扎实的路径。
如今的 AI 系统能够撰写文章、生成代码、总结复杂观点,并以惊人的流畅度进行对话。然而,这些同样的系统仍难以完成在人类看来很直观的任务:可靠地追踪变化中的物体、在陌生情境中进行组合式推理,或区分真实与看似合理的虚构。这些矛盾引发了关于 AI 的两极化争论。有些人将当前系统视为类人智能的早期形式;另一些人则将其贬为复杂的自动补全。
在近期的跨学科研究中——包括 Adam Frank、Marcelo Gleiser 和 Evan Thompson 的 The Blind Spot(在新标签页中打开),以及 DeepMind 研究员 Alexander Lerchner 的 The Abstraction Fallacy(在新标签页中打开)——一种不同的图景正在浮现。与其追问 AI 系统是否正变得具有人类意义上的智能,这些方法提出了一个更基本的问题:如果 AI 系统之所以能运作,是因为它们依赖于植根于人类认知的结构呢?这种受 Edmund Husserl 现象学启发的视角转变,有助于理解现代 AI 的能力与局限。
在我们最近的论文 The Origins of Artificial Intelligence in Natural Intelligence 中,我们认为,现代 AI 系统既不应被理解为人类心智,也不应被视为微不足道的统计把戏。相反,它们延展的是源自人类认知本身的结构。论文进一步借鉴 Husserl 的现象学,提出语言已经包含了人类理解的沉积结构——这些结构是 AI 系统学习建模并加以延展的对象。这一视角有助于解释当代 AI 的能力与边界。
人类感知并不是对感官数据的简单被动接收。我们体验到的世界,是稳定事物在变化中展开:当我们绕着一个杯子移动时,它仍然是同一个杯子;即使一个个音符消逝,旋律仍然可以被辨认。语言通过以概念形式表达这些稳定结构而产生。诸如“红色”“圆形”或“大于”等词语,表达的是源自生活经验的关系。
大语言模型学习的是这一语言世界中的统计关系。它们捕捉概念在海量人类文本中往往如何相互关联。这解释了为什么 AI 系统能够在许多领域给出连贯回应。但这也解释了它们为何会产生幻觉。人类仍需对世界负责:经验会不断修正我们的预期和信念。相比之下,AI 系统延展的是文本内部的模式。它们能够以惊人的流畅度延续一条推理线索,但缺乏那种使意义和真理扎根的、与世界的生活性接触。
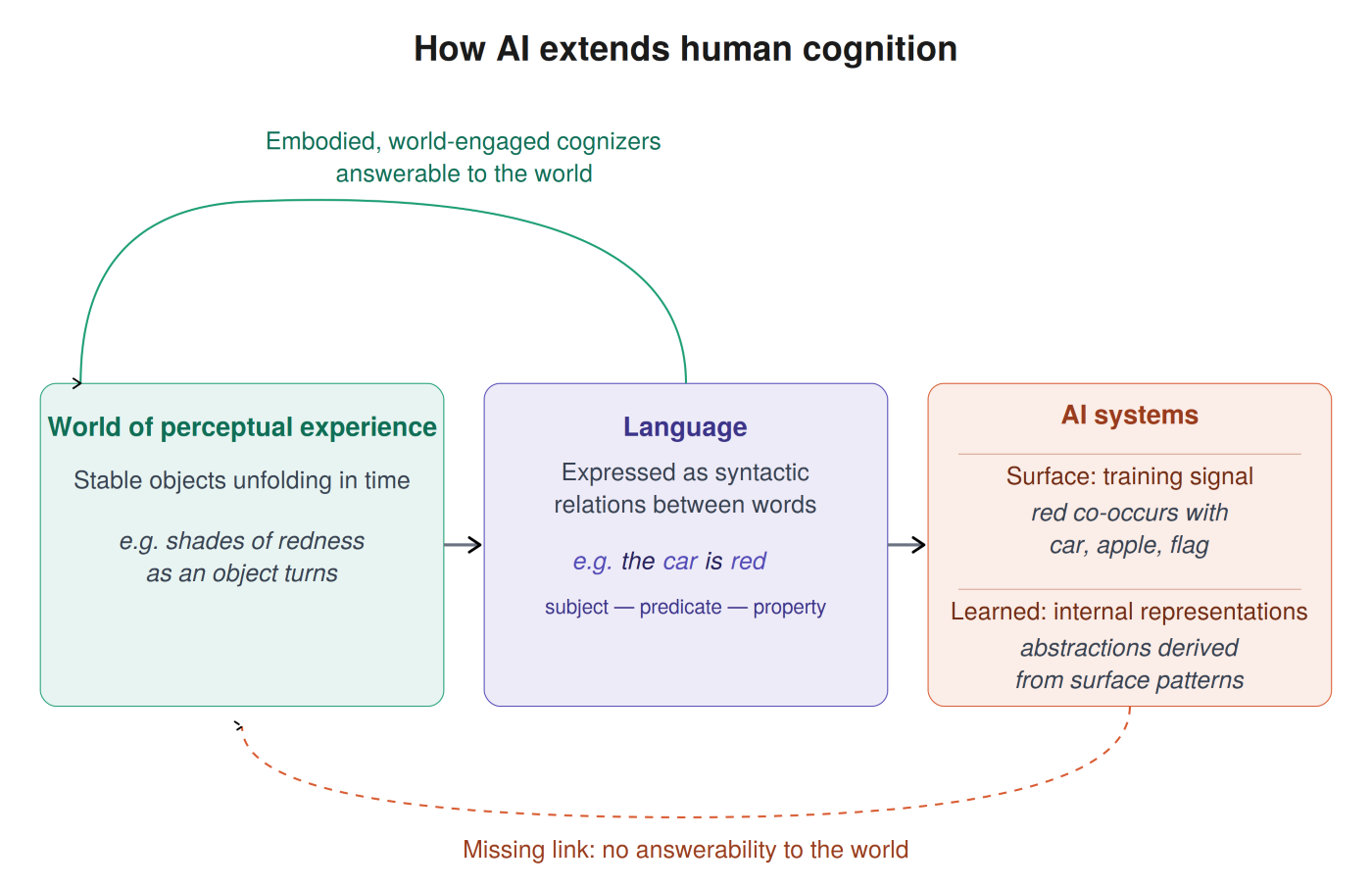
这一框架有助于解释 AI 研究中反复出现的若干挑战。其中之一是“组合性鸿沟”——语言模型在熟悉的推理模式上表现良好,却在被要求以真正新颖的方式组合概念时失败。越来越多的研究显示,更大的模型在流畅度和事实回忆上的提升,远快于在真正组合式推理上的提升。从我们的视角看,这并不只是工程限制,而是一种结构性边界:AI 系统可以延展语言中已经沉积的模式,但并不具备人类那种面向世界的理解,因而无法生成真正新的概念关系。
类似的模式也出现在结合语言与视觉的多模态系统中。这些系统往往能够正确标注图像,却仍然无法对物体及其组成部分进行稳健推理。它们学习的是视觉模式与语言之间的相关性,而不是像人类那样感知在时间中展开的稳定物体。其结果是,系统在熟悉模式中显得流畅得令人印象深刻,但在熟悉模式之外却出人意料地脆弱。
这一视角也重新界定了关于 AI 安全的争论。公共讨论常常在对“失控超级智能”的恐惧与认为 AI 并不构成有意义风险的说法之间摇摆。我们的研究表明,这两种极端都误解了当前系统的性质。最直接的风险并非来自 AI 具有人类般的意图,而是因为它能够延展推理模式,却不承担对世界的反思性责任。系统可能生成有说服力但缺乏根基的输出,大规模自动化有缺陷的决策,或在嵌入治理不善的环境时执行有害行动。
这有助于解释为什么 AI 安全正日益从模型安全转向系统安全。在实践中,组织已经依赖分层保障措施——行业中越来越常称为“harnesses”的机制——来约束、验证和监控 AI 行为。我们的论文认为,这些机制并非临时补丁,而是反映了 AI 架构本身的某种根本特征:可信行为来自 AI 系统构建者对其行为所承担的责任,而这种责任不能委托给模型,也不能与模型共同承担。
这一解释与企业日益采用的可信 AI 部署方式高度一致。组织需要能够延展人类智能、同时仍可治理、可审计并与人类监督保持一致的系统。将 AI 理解为一种派生的智能形式,有助于澄清为什么分层治理、评估和运营控制如此重要。
展望未来,我们认为现象学提供的不仅是对 AI 的批判,也是一种理解其前景的框架。AI 系统揭示了关于人类认知本身的深刻事实:意义可以被形式化、延展,并以强大的新方式扩大规模。因此,AI 的核心社会风险在于割断其源自人类经验与认知的阶梯——将 AI 误解为一种削弱我们人性的竞争性智能,并由此反过来削弱 AI 本身真正的前景。
因此,问题并不在于 AI 是否会取代人类智能,而在于我们如何负责任地构建能够延展人类理解、同时仍扎根于这种理解所由产生的世界的系统。如果我们将 AI 系统误认为自主心智,就有可能过度信任它们;如果我们将其贬为微不足道的把戏,就可能忽视我们这个时代最重要的技术发展之一。更扎实的解释会同时承认这两个事实:AI 是人类智能的真实延展——也正因为如此,人类仍然要对其如何被理解、治理和使用负责。
在新标签页中打开





