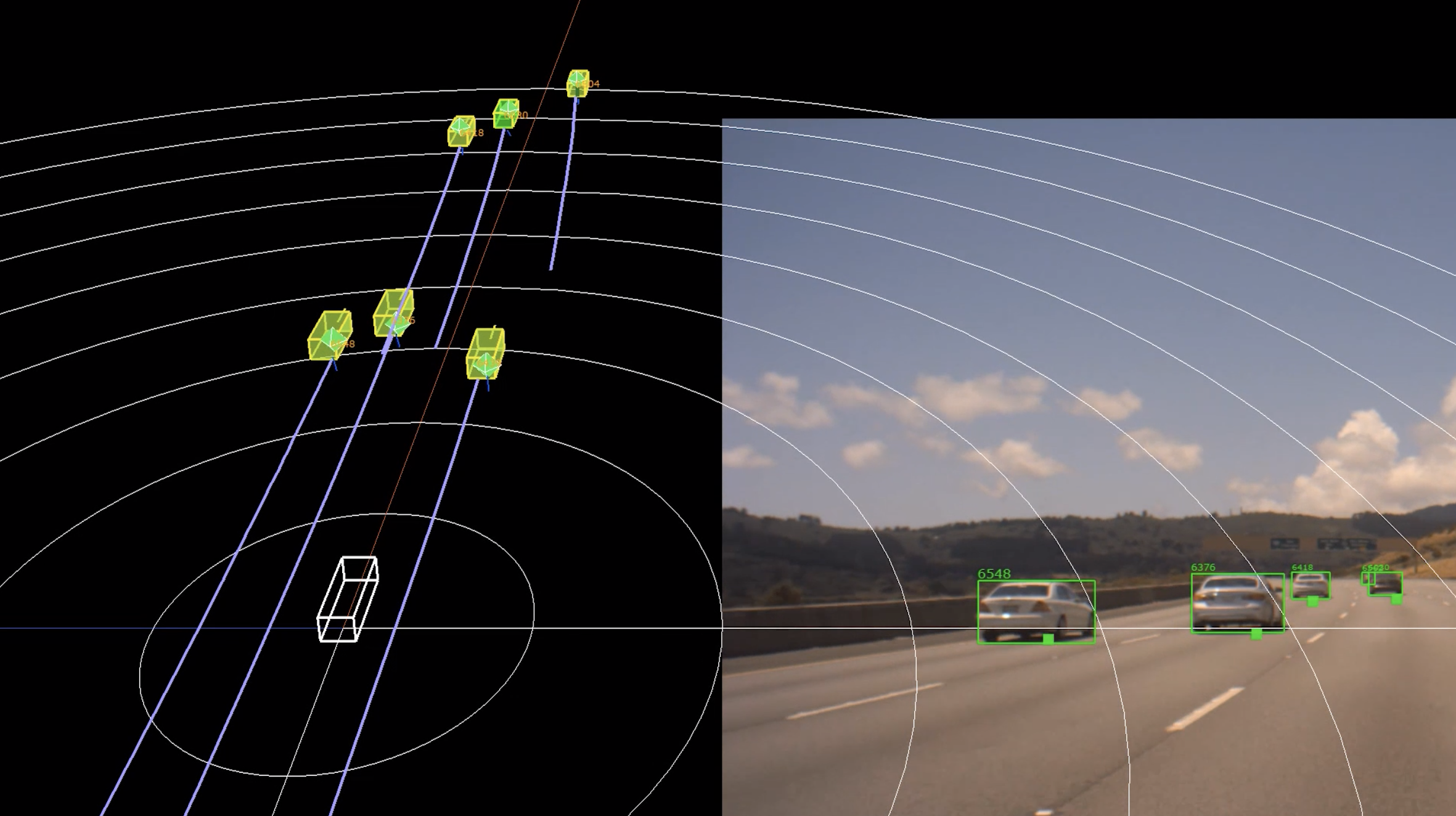
中文内容
在当前汽车雷达的状态下,机器学习工程师无法使用与摄像头等效的原始 RGB 图像。相反,他们使用雷达恒虚警率(CFAR)的输出,这类似于计算机视觉(CV)中的边缘检测。尽管雷达多年来一直是车辆级感知的核心组成部分,但通信和计算架构并未跟上 AI 趋势以及 L4 级自动驾驶需求的发展。
真正的 3D/4D“图像”信号则是在边缘设备内部处理的。雷达输出目标物,或者在某些情况下输出点云,这类似于摄像头输出经典 CV Canny 边缘检测图像。

NVIDIA DRIVE 上的集中式雷达处理改变了这一模式:原始模数转换器(ADC)数据被传输到集中式计算平台。随后,由专用 NVIDIA Programmable Vision Accelerator(PVA)硬件加速的软件定义流水线会处理从原始 ADC 样本到点云的所有环节,而 GPU 则预留用于数据流任意阶段的 AI 使用。在这种范式下,机器学习 AI 系统不再受限于边缘检测,而是可以利用全保真的雷达图像,使可用信息位数增加约 100 倍。

通过移除边缘计算雷达内部的高功率数字信号处理器/微控制器单元(DSP/MCU),集中式雷达以精简的印刷电路板(PCB)回归其射频(RF)本源。该设计使单元成本降低超过 30%,体积减少约 20%,实现超薄外形。借助中央域控制器更优的能效,整体系统功耗下降约 20%。这一创新不仅重塑了硬件设计,也与全球绿色能源趋势高度契合。
在这篇博客中,我们将解释集中式雷达处理如何在 DRIVE 上运行,内容包括:
- 为什么标准雷达模型会限制更高级别的自动驾驶,尤其是 L4 技术栈,对雷达数据的利用
- 原始 ADC 数据如何被摄取并移入 DRIVE 内存
- PVA 如何在不占用 CPU 或 GPU 的情况下处理雷达信号处理
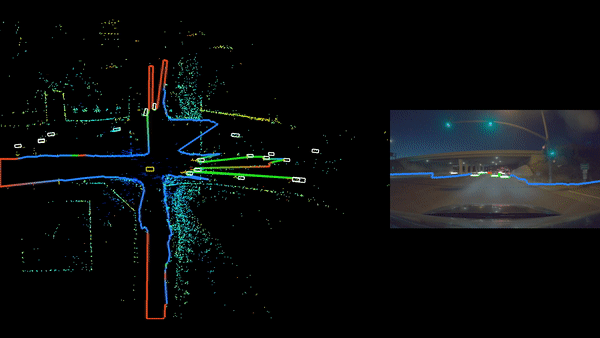
在本次分析中,NVIDIA 与 ChengTech 合作,验证了在 DRIVE 上使用量产级硬件进行集中式计算雷达处理;ChengTech 是首个加入 DRIVE 平台的原始雷达合作伙伴。
在上周的 GTC 2026 上,NVIDIA 和 ChengTech 展示了这条流水线在 DRIVE AGX Thor 上使用量产 ChengTech 雷达单元实时运行。
集中式雷达处理如何扩展雷达感知能力
大多数量产汽车雷达采用边缘处理架构。每个传感器单元都集成了自己的片上系统(SoC)或现场可编程门阵列(FPGA),在板端运行固定的信号处理链,并向中央高级驾驶辅助系统电子控制单元(ADAS ECU)输出稀疏点云。这使集成保持相对简单,并限制了传感器与计算平台之间所需的带宽。
然而,其权衡取舍值得注意:
- 点云仅发送峰值检测结果,所携带的数据量比雷达前端产生的原始 ADC 采样少约 100 倍。例如,在我们的配置中,长距雷达每帧产生 6 MB 的原始 ADC 数据,而点云形式仅为 0.064 MB。摄取原始或轻度处理雷达数据的集中式架构可以利用更多底层信号统计信息,从而提升感知能力。
- 边缘处理中的雷达占空比通常低于 50%(即雷达处于发射状态的时间占比),这通常意味着较低的帧率,例如约 20 帧每秒(FPS),和/或目标上的功率降低。这对传统 ADAS 触发器来说是可行的,但对于大型、具备时间感知能力的模型而言,会留下未被利用的时间分辨率。
- 边缘雷达 ECU 严格的内存和带宽限制意味着,它必须丢弃中间频域产物,例如距离快速傅里叶变换(range-FFT)立方体、多普勒 FFT(Doppler-FFT)立方体和角度 FFT(angle-FFT)图,尽管这些恰恰是近期基于学习的雷达模型和信号级融合方法最希望访问的信号视图,正如 Raw High-Definition Radar for Multi-Task Learning (CVPR 2022) 和 T-FFTRadNet: Object Detection with Swin Vision Transformers from Raw ADC Radar Signals (ICCV Workshops 2023) 所展示的那样。
- 雷达信号处理流水线在边缘硬件上是固定的,并受到严格的散热和计算限制。集中式处理允许 OEM 或系统集成商启用更深的网络、更高的输入分辨率以及多传感器联合模型,而这些在小型雷达 SoC 上并不实际。
L4 技术栈正越来越多地采用大型模型和视觉-语言-动作(VLA)架构,这些架构直接从原始传感器数据中学习,而不是从后处理后的输出中学习。这些系统受益于所有传感器模态中的密集低层信号,就像视觉模型受益于原始相机帧而不是压缩特征一样。对于雷达而言,这意味着需要重新思考处理发生的位置和方式。
NVIDIA DRIVE 上的集中式计算雷达
集中式雷达处理通过将信号处理链从传感器转移到 DRIVE 平台来解决这些限制。射频前端和天线仍保留在传感器硬件上,但这些单元不再运行固定的嵌入式流水线,而是通过高带宽链路将原始 ADC 样本流式传输到 DRIVE DRAM 中。雷达信号处理的所有阶段都在 DRIVE 的专用硬件 PVA 上运行,开发者可以在其中控制完整流水线。
三个组件协同实现这一功能:
1) 配置为原始 ADC 输出的传感器 2) 一个将原始数据摄取并同步到 DRIVE 内存中的驱动程序栈 3) 一个基于 PVA 的计算库,用于处理所有雷达 DSP
这些组件共同使雷达成为 DRIVE 上一种集中管理、由加速器支持的模态,与摄像头和激光雷达在现代 L4 架构中的集成方式保持一致。
将原始 ADC 数据移入 DRIVE 内存
第一步是将原始 ADC 数据从传感器可靠且大规模地传输到中央内存。在我们的配置中,车辆上部署了五个传感器:
- 一个 ChengTech 8T8R 前向雷达
- 四个 ChengTech 4T4R 角雷达
所有五个单元均配置为输出原始 ADC 数据,而不是经过嵌入式处理的点云。整个阵列的原始数据总速率约为 540 MB/s,而等效的基于点云的雷达带为 4.8 MB/s。
摄取栈通过平台级雷达驱动程序处理这一点,这些驱动程序:
- 将传感器配置为原始输出模式
- 以所需吞吐量将 ADC 帧流式传输到 DRIVE DRAM
- 通过一致的、与硬件无关的 API 呈现雷达帧
- 与相机采集共享硬件同步信号,使雷达帧和图像帧对齐,以用于多模态融合和训练
从应用程序的角度来看,雷达数据以带时间戳、已同步的缓冲区形式到达 DRIVE 内存,可直接进入信号处理阶段。
在 PVA 上运行雷达信号处理
一旦原始 ADC 缓冲区进入内存,信号处理链便完全在 PVA 上运行,从而让 GPU 可用于下游 AI。该流程涵盖雷达 DSP 的标准阶段:
- 沿快时间轴执行距离 FFT,为每个啁啾生成距离剖面
- 沿慢时间轴执行多普勒 FFT,估计每个距离单元的径向速度
PVA 正是为这类工作负载而设计的。下方图 3 展示了 DRIVE AGX Thor 中 PVA 的高层架构。PVA 引擎的核心是先进的超长指令字(VLIW)、单指令多数据(SIMD)数字信号处理器(DSP)。它结合了向量处理单元(VPU)、专用 DMA 引擎和片上本地内存(VMEM),以提供持续的高吞吐量 FFT 性能,并具备确定性的内存访问行为。

PVA 能够以低功耗提供高性能,并可在 DRIVE 平台上作为异构计算流水线的一部分,与 CPU、GPU 及其他加速器异步并行运行。在五雷达配置中,将完整雷达库运行在 PVA 上而不是 GPU 上,可以显著降低 GPU 利用率,并为感知和规划工作负载释放 GPU 容量。
为支持可定制流水线,PVA Solutions 提供了一组高度优化且常用的雷达算子。这使开发者能够组装和定制流水线,而无需从头实现每一个内核。此外,NVIDIA Programmable Vision Accelerator Software Development Kit(PVA SDK)也面向希望构建自有专有“秘密配方”的开发者提供。
在我们的配置中,PVA 以每秒 30 帧处理来自全部五个雷达单元的原始数据。所有雷达 DSP 工作都保留在 PVA 上,从而最大限度减少 CPU 和 GPU 使用,并使这些资源可用于感知网络、规划模块及其他工作负载。PVA 使用内存子系统中的预留带宽。
每个阶段的中间输出都会写回 DRAM,并保持可供堆栈其余部分访问。这意味着:
- 距离-多普勒立方体和角度 FFT 热力图可以被可视化或记录以供分析。
- 感知模型可以直接使用点云前表示。
- 多雷达融合可以在最终检测之前于信号层面运行,从而提高整个传感器阵列的噪声抑制能力和目标分辨率。

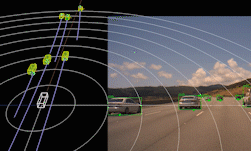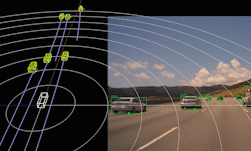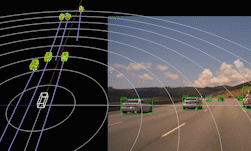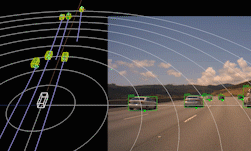
上方图 4 中的距离-多普勒图展现出传统边缘处理雷达从不导出的密集频谱结构。下方图 5 中,提取了该距离-多普勒图的峰值,并执行测角,从而生成稀疏点云。

将雷达信号数据暴露给感知系统和物理 AI
在 DRIVE 上集中处理雷达,不仅仅是去除每个传感器上的 SoC 或 FPGA。它还增强了平台上运行的感知和 AI 系统所能看到的内容。
当中间雷达数据存储在 DRAM 中时,几种模式变得可行:
- 近期的研究,如 Raw High‑Definition Radar for Multi‑Task Learning(CVPR 2022)和 T‑FFTRadNet: Object Detection with Swin Vision Transformers from Raw ADC Radar Signals(ICCV Workshops 2023),在原始 ADC 信号或距离/多普勒/角度 FFT 表示上训练神经网络,而不是仅在稀疏点云上训练,从而实现更丰富的雷达感知。
- 设计早期融合模型,使用同步的原始数据或点云生成前数据来结合雷达和摄像头特征。
- 在信号层面实现多个雷达单元之间的相干融合,以提高覆盖范围、抑制干扰并应对恶劣条件。
对于已经将摄像头和激光雷达视为一等原始模态的 L4 技术栈,集中式雷达弥合了这一差距。雷达可以以与其他传感器相同的数据保真度,参与 VLA 风格的训练流程和其他大模型方法,并使用 DRIVE 已经提供的同一套集中式、软件定义基础设施。
集中式计算雷达是 L4 感知的未来
DRIVE 上的集中式雷达处理旨在解决一个简单的局限:当今的标准雷达只能为 L4 技术栈提供对更丰富信号的稀疏、分散视图。通过将雷达作为一种由加速器支持的软件定义模态纳入 DRIVE,你可以在 DRAM 中获得完整的雷达信号,并在专用硬件而非 GPU 上进行处理,同时与摄像头和激光雷达对齐,供模型学习。
基于这一计算和软件基础,NVIDIA DRIVE Hyperion 参考架构可以将雷达集成到与摄像头和激光雷达相同的集中式、软件定义管线中,为 OEM 提供面向量产的集中式雷达蓝图。
入门指南
要开始评估这种方法,请与您的雷达供应商合作以启用原始输出模式,并与您的感知团队协作开发更丰富的基于雷达的模型和融合方案。
要推进到量产阶段,请与受支持的雷达供应商和其他 NVIDIA DRIVE 生态系统合作伙伴联系,并联系您的 NVIDIA 代表以获取 PVA SDK 和 PVA Solutions 的访问权限。
致谢 感谢 Mark Vojkovich、Mehmet Umut Demircin、Michael Chen、Balaji Holur、Sean Pieper、Mladen Radovic、Nicolas Droux、Kalle Jokiniemi、Ximing Chen、Romain Ygnace、Sharon Heruti、Jagadeesh Sankaran、Zoran Nikolic、Ching Hung、Yan Yin、Qian Zhan、Dian Luo、Rengui Zhuo(ChengTech)、Feng Deng(ChengTech)、Mo Poorsartep、Cassie Dai 和 Wonsik Han 的贡献。
标签