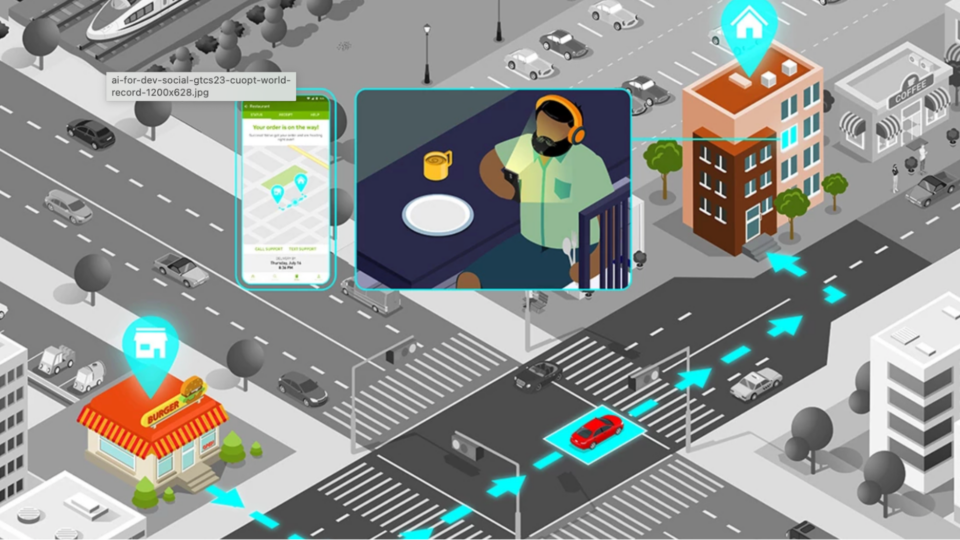
中文内容
现代供应链持续面临需求波动、成本不稳定、产能受限以及相互依赖的决策等压力。传统上,专门的运筹学(OR)团队通过将业务问题转化为数学模型来解决这些问题。这个过程可能需要数周时间,并且往往产生脆弱的解决方案,在条件变化时难以适应。
Agentic AI 正在改变这一范式。通过将 LLM 的推理能力与 GPU 加速求解器的计算能力相结合,AI 智能体可以理解用自然语言表达的业务问题,并在数秒内将其转化为严谨、优化的决策。
这一方法的核心是 agent skills——一种用于以专业知识和工作流扩展智能体的开放格式。Skills 作为一种封装机制,动态加载正确的流程上下文,并提升智能体在特定任务上的性能。
本文概述了 NVIDIA cuOpt agent skills 的核心内容、其重要性,以及它们如何协同工作:通过将自然语言业务问题转换为数学模型,并使用 NVIDIA cuOpt 决策优化求解器进行求解,从而加速一个多周期供应链规划用例。
如何使用 NVIDIA cuOpt agent skills
NVIDIA cuOpt 是一款 GPU 加速的决策优化引擎,可求解线性规划(LP)、混合整数规划(MIP)和路径规划问题,其速度比基于 CPU 的求解器快数个数量级。通过将 cuOpt 作为 agent skill 提供,LLM 可以把繁重的数学计算交给 GPU,同时专注于理解业务问题、收集数据并返回可执行的结果。
以下步骤概述了如何设置和使用 NVIDIA cuOpt 供应链智能体参考工作流;该工作流使用 cuOpt agent skills,通过智能体驱动的工作流执行 GPU 加速的供应链优化。
第 1 步:设置环境
配置一套带有 NVIDIA GPU 的系统,并安装 NVIDIA Container Toolkit,使容器化工作负载能够访问 GPU。可以在自己的基础设施上运行,也可以部署 Brev Launchable,在云端获得预配置的 GPU 环境,其中已安装 NVIDIA CUDA、Docker 和其他前置条件。
然后,安装 cuOpt agent 包及其依赖项。该演示应用已完成容器化,确保可复现性,并简化在开发、预发布和生产环境中的部署。
第 2 步:初始化智能体
该智能体使用 MiniMax M2.5 作为其推理模型。可以使用公开托管的端点,或者为获得最佳性能,在本地部署 NVIDIA NIM。
其余部署流程很直接。由于应用已容器化,一条简单的 Docker Compose 命令即可在各自端口启动 UI 和 Phoenix tracing,你可以在新标签页中打开它们。
源代码包含若干可供智能体使用的 skills。这些 skills 充当定义明确的函数签名,LLM 可以调用它们。每个 skill 都封装一种特定的优化能力(例如生产计划、库存优化或路径优化)及其输入/输出模式。以这种方式注册 skills,使 LLM 能够根据用户意图动态发现并调用它们。
第 3 步:提供供应链数据
向智能体提供优化所需的特定领域数据。对于多周期规划问题,通常包括:
- 按产品、地区和时间周期划分的需求预测。
- 各设施的生产能力和单位成本。
- 库存持有成本和存储上限。
- 运输成本和交付周期。
- 服务级别协议或最低生产批量等业务约束。
在生产部署中,这些数据会直接从规划系统中提取。出于演示目的,该参考工作流使用了模拟真实世界结构的虚拟数据集。
第 4 步:调用 agent skills
用自然语言运营目标提示智能体,例如:“生成一个 12 周的生产和库存计划,在满足所有配送中心预测需求的同时最小化总成本。”
在底层,该工作流使用 LangChain Deep Agents 生成一个子智能体层级结构,每个子智能体负责工作流的一部分。编排智能体会对目标进行推理,将其分解为多个步骤并委派任务。一个子智能体可能负责提取并验证输入数据,另一个可能负责构建数学模型,还有一个可能负责调用 cuOpt skill。
当调用 cuOpt skill 时,智能体会向 cuOpt 求解器传递一个结构化载荷,其中包含决策变量、目标函数和约束条件。
第 5 步:获取解决方案并采取行动
cuOpt 利用大规模并行性在 GPU 上执行优化,以比传统 CPU 求解器更快地评估解空间。找到解之后,智能体会接收优化后的决策变量(例如每个周期各产品的生产量、需要持有的库存量或发往何处),并将其转换回人类可读的摘要。这通常包括总成本、产能利用率和约束松弛量等关键指标。
结果是一份可执行计划,决策者可以审查它,通过后续提示进一步优化,或直接推送到下游执行系统。
观看以下教程,了解如何使用 NVIDIA Brev launchable 设置并运行 cuOpt 供应链智能体参考工作流。
可扩展的 agentic 架构
cuOpt 供应链智能体参考工作流是一个简化的起点。你可以使用更多 agent skills 和编排模式对其进行扩展,以更好地适配生产级企业工作负载。下方架构图展示了一种可扩展模式,用于围绕核心智能体工作流添加企业级协调、治理、可靠性和稳健性。

数据集和 GitHub 仓库的快速链接
在 GitHub 上开始使用此 cuOpt agent 工作流。按照快速入门指南在本地运行示例,或使用 NVIDIA Brev Launchable 在云端启动一个 GPU 实例,其中包含预加载的 Jupyter Notebook,可引导你部署该示例。
技术前置条件:
- 在 NVIDIA GPU 上使用 vLLM 部署 Minimax LLM(例如,八块 NVIDIA A100 Tensor Core GPU)。
- Docker 和 Docker Compose(配合 NVIDIA Container Toolkit)。
- 来自 build.nvidia.com 的 NVIDIA API 密钥。
开始使用
使用 NVIDIA NeMo Agent Toolkit 部署 NVIDIA cuOpt Agent 参考工作流,并使用内置优化 skills,或创建你自己的 skills。运行结构化查询,将特定领域约束集成到工作流中,并扩展 cuOpt skills,以基准测试指标并优化你自己的特定领域用例。
订阅 NVIDIA 新闻,并在 LinkedIn、X、Discord 和 YouTube 上关注 NVIDIA AI,以获取 NVIDIA cuOpt 的最新信息。
访问 cuOpt 入门页面,获取 Google Colab、NVIDIA API Catalog、GitHub 和 NVIDIA AI Enterprise 相关资源。
在 NVIDIA forum 和 Discord 上与开发者社区互动。
标签