中文内容
从训练好的 AI 模型到生产环境的路径本应顺畅,但现实中很少如此。许多团队投入数周时间微调模型,却发现导出为部署格式会破坏层结构、输入形状导致运行时故障,或者版本不匹配会在无声无息中降低性能。这些问题统称为流水线摩擦,它们会让组织付出时间、金钱和竞争优势的代价。
本文提供了可执行的最佳实践,用于消除 AI 模型服务流水线中最常见的摩擦来源。结果是具体可见的:API 在真实流量下响应更快。每块 GPU 承载更多请求。针对高峰时段的扩展变得顺畅且低压力。每次推理的成本下降。部署本身也不再是每次发布中容易出问题的环节。
什么是 AI 模型服务中的流水线摩擦?
流水线摩擦是指任何会减缓或扰乱模型从训练到生产推理这一过程的障碍。与会产生明确错误消息的 bug 不同,摩擦通常表现为细微的低效率:例如,模型消耗的 GPU 内存是预期的两倍,或者推理服务器在负载下丢弃请求,又或者某个部署在一种 GPU 架构上可以运行,但在另一种架构上失败。
流水线摩擦最常见的来源可归为四类:
- 模型导出问题:这些问题出现在从 PyTorch 或 TensorFlow 等训练框架转换为优化的推理格式时
- 不支持的操作:目标运行时无法识别自定义或近期引入的层
- 动态输入尺寸:会导致形状不匹配,或迫使进行不必要的重新编译
- 版本不匹配:库、驱动程序和硬件之间的不匹配会引入静默故障或性能回退
每个类别都需要特定的工具和技术。成熟的解决方案生态系统已经存在,系统地应用这些方案可以在摩擦进入生产环境之前消除其中的绝大多数。以下各节将详细介绍这些类别,以及另外几种最小化流水线摩擦的方法。
如何解决模型导出问题
大多数团队使用 PyTorch 或 TensorFlow 进行训练,然后导出为 ONNX 作为中间表示,再使用 NVIDIA TensorRT 进行优化。许多问题都会在这个转换步骤中显现:不受支持的动态控制流、缺少 ONNX 对应项的操作,以及训练框架生成的张量形状与导出工具预期的张量形状之间的不匹配。
最佳实践 1:尽早并经常验证导出。将导出验证纳入 CI/CD 工作流,使每个模型检查点都经过可导出性测试。这种方法可以在有问题的架构决策嵌入代码库之前将其发现。
最佳实践 2:有意地使用 ONNX 算子集版本控制。ONNX 支持多个算子集版本。较新的算子集支持更多操作,但可能与较旧的运行时不兼容。明确固定你的算子集版本,并记录原因。升级时,要针对你的目标推理运行时进行充分测试。
最佳实践 3:在导出前简化模型图。移除仅用于训练的组件,例如 dropout 层、辅助损失头和调试钩子。使用图优化过程来折叠批量归一化并消除冗余操作。更简洁的图导出更可靠,运行也更快。
TensorRT 提供内置的图优化功能,可自动处理其中许多转换,包括融合层、为你的特定 GPU 选择最优内核,以及消除不必要的内存拷贝。

如何处理不受支持的操作
即使采用谨慎的导出实践,你仍会偶尔遇到目标运行时无法原生支持的操作。这在引入新型注意力机制、自定义激活函数或专用归一化层的前沿架构中尤为常见。如果不进行干预,TensorRT 要么会回退到较慢的执行路径,要么会完全构建失败。
最佳实践 4:对不受支持的算子使用 TensorRT 插件扩展。插件使你能够用 C++ 或 CUDA 编写自定义实现,并将其直接集成到优化流水线中,从而受益于与内置操作相同的内核选择和内存优化。相比图分区,这种方式更可取,因为图分区会在不同运行时之间引入内存拷贝,并阻碍跨层优化。
最佳实践 5:在编写自己的插件之前,先检查 TensorRT 插件仓库。NVIDIA 维护着一个插件仓库,社区贡献也在定期扩展该仓库。
最佳实践 6:在设计模型时考虑部署。当选择架构时,应尽早评估特殊操作的部署成本。有时存在功能等效但支持更好的操作,选择它可以节省数周的工程时间。
如何管理动态输入大小
许多 AI 应用必须管理大小各异的输入:不同长度的句子、不同分辨率的图像,或随流量波动的批次。如果 TensorRT 引擎是为固定输入形状构建的,任何偏离都需要填充(浪费计算)、调整大小(可能改变行为)或重建引擎(成本高且速度慢)。
最佳实践 7:在 TensorRT 中定义动态输入配置文件。优化配置文件为每个输入张量指定最小、最优和最大维度,从而创建一个无需重新编译即可处理一系列尺寸的单一引擎。例如,对于尺寸从 224×224 到 1024×1024 的图像,定义一个以上述边界为范围、并将最常用分辨率设为最优尺寸的配置文件。
最佳实践 8:针对不同的工作负载模式使用多个优化配置文件。如果你的应用在不同时间服务于本质上不同的输入模式,例如低流量时的单图像推理和高峰时段的大批量推理,请为每种模式定义单独的配置文件。TensorRT 会在运行时以极低开销在它们之间切换。
最佳实践 9:在完整输入范围内进行基准测试。使用 trtexec 测量最小、最优和最大维度下的延迟和吞吐量。这会揭示引擎在不同内核实现之间切换时出现的性能断崖。
如何防止版本不匹配
版本不匹配是最隐蔽的摩擦来源之一,因为它们通常完全不会产生错误。模型可能会以降低的准确率运行,或者运行时可能会在没有警告的情况下回退到较慢的代码路径。这些静默故障可能会持续数月。
典型部署栈中的版本矩阵非常复杂:训练框架、ONNX 导出器、TensorRT、CUDA Toolkit、cuDNN、GPU 驱动程序和操作系统。任意两者之间的不匹配都可能导致问题。
最佳实践 10:固定并记录整个依赖栈。创建一份版本清单,列出每个组件及其精确版本号。将其与模型工件存放在一起。
最佳实践 11:使用容器以实现可复现性。NVIDIA NGC 容器捆绑了兼容版本的 TensorRT、CUDA、cuDNN 和常用框架,消除了开发、测试和生产环境中最常见的版本不匹配问题。
最佳实践 12:隔离测试升级。一次只更改一个组件,并在继续之前运行完整的测试套件。
既然已经介绍了四个主要类别,以下各节将探讨更多减少流水线摩擦的方法。
如何分析和调试你的流水线
即使是无摩擦的流水线,也可能存在隐藏在表面之下的性能问题。有效的性能分析至关重要。
最佳实践 13:使用 TensorRT 命令行封装工具 trtexec 进行基线性能测量。在隔离环境中运行模型,以在集成到服务系统之前建立基线延迟和吞吐量。如果此处性能不达标,问题就在模型或引擎配置中。
最佳实践 14:使用 NVIDIA Nsight Deep Learning Designer 进行层级分析。它为模型图中的每个操作提供详细的计时信息,便于发现瓶颈,例如受内存限制的操作、低效的数据布局,或阻碍融合的操作。
最佳实践 15:使用 NVIDIA Nsight Systems 进行系统级分析。Nsight Systems 在统一时间轴上可视化 CPU 和 GPU 活动,揭示预处理中的 CPU 瓶颈、不必要的同步点,以及推理调用之间的 GPU 空闲时间。这对于优化端到端吞吐量至关重要,而不仅仅是模型推理延迟。

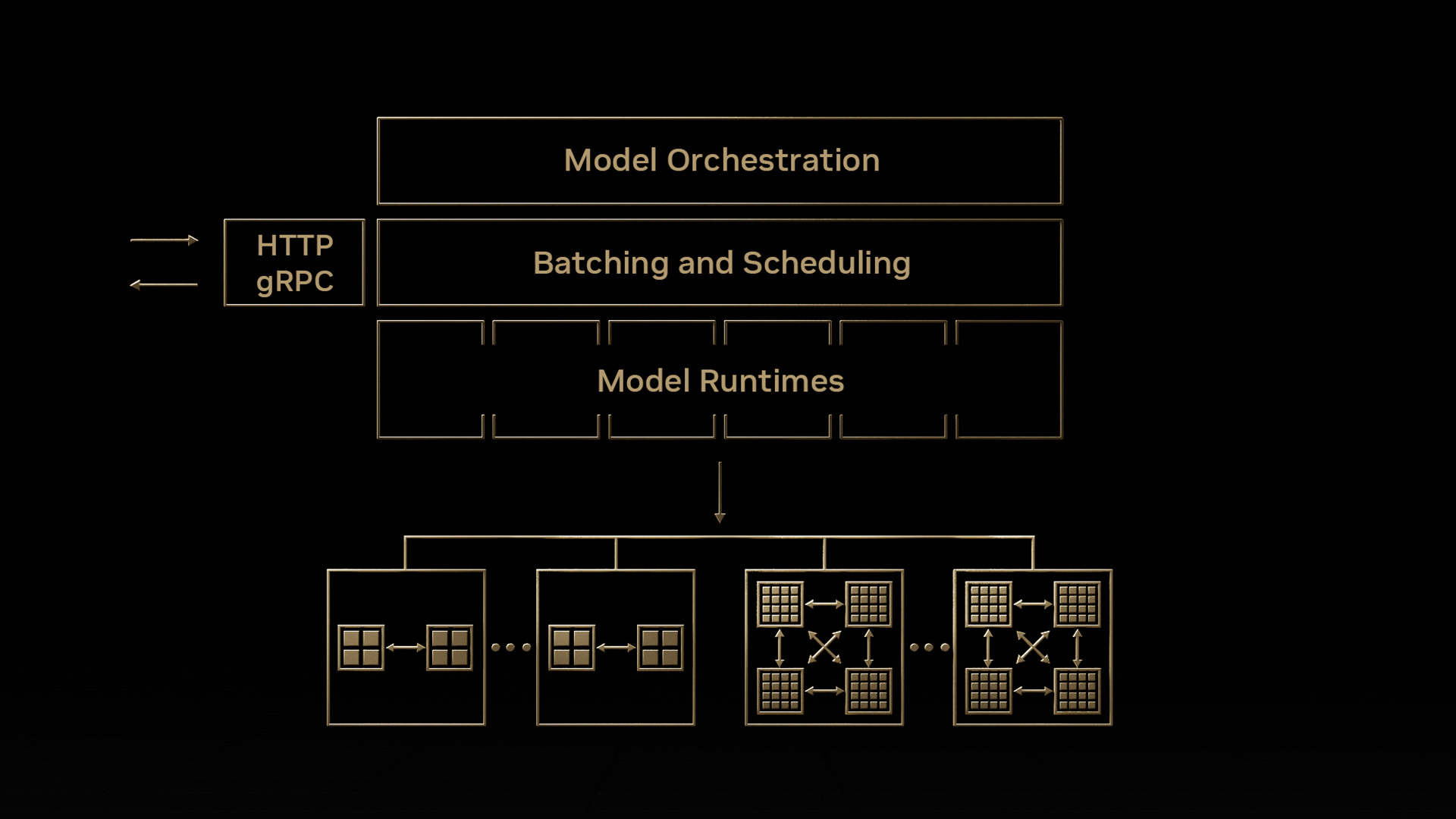
如何将 TensorRT 与 Dynamo-Triton 集成
优化模型只是成功的一半。在生产环境中,你需要处理并发请求、管理模型版本、在 GPU 之间平衡负载,并保持高可用性。NVIDIA Dynamo-Triton(前身为 NVIDIA Triton Inference Server)是一个开源服务平台,原生支持 TensorRT 引擎以及其他框架,从而构建出可用于生产的技术栈。

最佳实践 16:在 Dynamo-Triton 中配置动态批处理,使其与你的 TensorRT 配置文件相匹配。将 Dynamo-Triton 中的最大批大小设置为与你的优化配置文件中的最大批维度一致,这样动态批处理后的请求始终落在优化范围内。
最佳实践 17:使用 Dynamo-Triton Model Analyzer 查找最优配置。它会系统地测试批大小、实例数量和并发级别的组合,以在满足延迟要求的同时最大化吞吐量。
最佳实践 18:通过 Dynamo-Triton 模型仓库实现模型版本控制。Dynamo-Triton 可同时提供多个版本,从而支持金丝雀部署和渐进式发布。将其与你的版本清单配合使用,以确保兼容性。

关于建立无摩擦流水线的更多提示
消除流水线摩擦需要将一些实践纳入你的工作流,以防止摩擦不断累积。创建一份部署检查清单,涵盖导出验证、性能基准测试、版本兼容性和生产配置。通过 CI/CD 流水线将其自动化。
投入监控能力,以检测生产环境中的回归问题。跟踪推理延迟、吞吐量、GPU 利用率和模型准确率。当任何指标偏离基线时,立即进行调查。
促进训练团队与部署团队之间的沟通。许多摩擦来源于训练期间的架构决策,这些决策会产生意料之外的部署后果。早期协作使团队能够做出明智的决策和权衡。
开始消除流水线摩擦
AI 模型服务流水线中的摩擦是一个可以解决的问题。TensorRT 通过动态输入配置和插件扩展提供优化。trtexec、Nsight Deep Learning Designer 和 Nsight Systems 等分析工具可提供对每一层的可视化洞察。Dynamo-Triton 负责生产环境中的服务提供和流量管理。
关键在于系统地应用这些工具。尽早验证导出结果,面向部署进行设计,谨慎管理版本,全面进行性能分析,并持续监控。其结果是更快的迭代、高效的资源利用,以及面向最终用户的一致性能。
TensorRT 和 Dynamo-Triton 在 NVIDIA/TensorRT 和 triton-inference-server/server GitHub 仓库中完全开源。TensorRT 使用 C++ 编写,并提供 C++ 和 Python API;Dynamo-Triton 提供 C++、Python 和 Java 客户端库。
二者均支持 Linux(Ubuntu、RHEL),其中 TensorRT 还支持 Windows。获得可复现环境的最快路径是从 NGC catalog 拉取预构建容器。
要开始使用,请浏览 TensorRT samples 目录。trtexec 可从 ONNX 模型构建引擎并对性能进行基准测试。ONNX-to-TensorRT 示例涵盖导出验证、优化配置文件和插件扩展。请查看 Dynamo-Triton Quickstart,了解模型仓库、动态批处理和 Model Analyzer 配置的详细信息。
标签