中文内容
从 cgroup v1 CPU shares 到 v2 CPU weight 的新转换方式
我很高兴宣布,已实现从 cgroup v1 CPU shares 到 cgroup v2 CPU weight 的改进转换公式。此增强解决了在使用 cgroup v2 的系统上运行 Kubernetes 工作负载时,CPU 优先级分配方面的关键问题。
背景
Kubernetes 最初是围绕 cgroup v1 设计的,其中 CPU shares 根据容器的 CPU requests 通过以下公式得出:
请注意,此公式中的 1024 是 cgroup v1 中默认的 cpu.shares 值,与 millicores 无关。例如,请求 1 CPU(1000m)的容器会得到(cpu.shares = 1000 \times 1024 / 1000 = 1024),请求 100m 的容器会得到(cpu.shares = 100 \times 1024 / 1000 = 102)。
一段时间后,cgroup v1 开始被其继任者 cgroup v2 取代。在 cgroup v2 中,CPU shares 的概念(范围为 2 到 262144,或 2¹ 到 2¹⁸)被 CPU weight 取代(范围为 [1, 10000],或 10⁰ 到 10⁴)。
随着向 cgroup v2 过渡,KEP-2254 引入了一个转换公式,用于将 cgroup v1 CPU shares 映射到 cgroup v2 CPU weight。该转换公式定义为:cpu.weight = (1 + ((cpu.shares - 2) * 9999) / 262142)
此公式将 [2¹, 2¹⁸] 中的值线性映射到 [10⁰, 10⁴]。

虽然这种方法很简单,但线性映射带来了几个重大问题,并影响性能和配置粒度。
先前转换公式存在的问题
当前转换公式会产生两个主要问题:
1. 相对于非 Kubernetes 工作负载的优先级降低
在 cgroup v1 中,CPU shares 的默认值为 1024,这意味着请求 1 CPU 的容器与 Kubernetes 范围之外的系统进程具有相同优先级。然而,在 cgroup v2 中,默认 CPU weight 为 100,但当前公式仅将 1 CPU(1000m)转换为约 39 的 weight——不到默认值的 40%。
示例:
- 请求 1 CPU(1000m)的容器
- cgroup v1:cpu.shares = 1024(等于默认值)
- cgroup v2(当前):cpu.weight = 39(远低于默认值 100)
这意味着迁移到 cgroup v2 后,Kubernetes(或 OCI)工作负载相对于非 Kubernetes 进程实际上会降低其 CPU 优先级。对于有许多在 Kubernetes 范围之外运行的系统守护进程、且预期 Kubernetes 工作负载具有优先级的部署来说,这个问题可能很严重,尤其是在资源匮乏的情况下。
2. 难以管理的粒度
当前公式会为较小的 CPU requests 生成非常低的值,从而限制了在容器内创建子 cgroups 以进行细粒度资源分配的能力(未来这可能会变得容易得多,更多信息见 KEP #5474)。
示例:
- 请求 100m CPU 的容器
- 正文:cgroup v1:cpu.shares = 102
- cgroup v2(当前):cpu.weight = 4(对于子 cgroup 配置来说过低)
在 cgroup v1 中,请求 100m CPU 会产生 102 个 CPU shares,从可管理性角度看,可以在主容器内创建子 cgroups,为不同进程组分配细粒度的 CPU 优先级。然而在 cgroup v2 中,只有 4 个 shares 很难在子 cgroups 之间分配,因为粒度不够。
随着计划允许非特权容器使用可写 cgroups,这一点变得更加相关。
新的转换公式
说明
新公式更复杂,但能更好地在 cgroup v1 CPU shares 与 cgroup v2 CPU weight 之间进行映射:
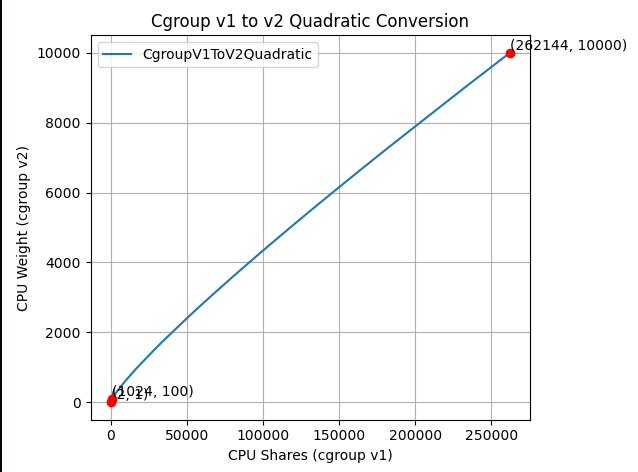
其思路是,这是一个二次函数,用于穿过以下数值点:
- (2, 1):两个范围的最小值。
- (1024, 100):两个范围的默认值。
- (262144, 10000):两个范围的最大值。
从视觉上看,新函数如下:
如果放大到重要部分:
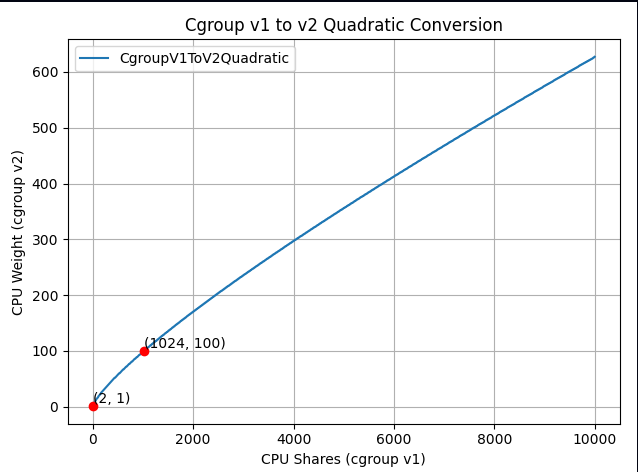
新公式“接近线性”,但经过精心设计,以巧妙方式映射这些范围,使上述三个重要点能够被穿过。
它如何解决这些问题
- 更好的优先级对齐:请求 1 CPU(1000m)的容器现在将得到 cpu.weight = 102。该值接近 cgroup v2 的默认值 100。这恢复了 Kubernetes 工作负载与系统进程之间预期的优先级关系。
- 改进的粒度:请求 100m CPU 的容器将得到 cpu.weight = 17(见此处)。这支持在容器内实现更好的细粒度资源分配。
采用与集成
此更改是在 OCI 层实现的。换言之,它并未在 Kubernetes 本身中实现;因此,新转换公式的采用完全取决于 OCI runtime 的采用情况。
例如:
- runc:新公式自版本 1.3.2 起启用。
- crun:新公式自版本 1.23 起启用。
对现有部署的影响
重要:如果某些使用者假定旧的线性转换公式,可能会受到影响。基于先前公式直接计算预期 CPU weight 值的应用程序或监控工具,可能需要更新以适配新的二次转换。这一点尤其适用于:
- 预测 CPU weight 值的自定义资源管理工具。
- 验证或期望特定 weight 值的监控系统。
- 以编程方式设置或验证 CPU weight 值的应用程序。
另请注意,从 cpu.weight 反向转换回 milliCPU 并不总能得到完全相同的原始值。信息丢失有两个来源:milliCPU 到 cpu.shares 的转换涉及整数截断(例如 100m 变为 102 shares,而不是 102.4);更重要的是,shares 到 weight 的映射是多对一的(例如 milliCPU 值 90 到 109 都映射到 cpu.weight = 17)。需要精确 CPU request 值的工具应直接从 pod spec 读取,而不是从 cgroup 参数推导。
Kubernetes 项目建议,在升级 OCI runtimes 之前,先在非生产环境中测试新的转换公式,以确保与现有工具兼容。
我可以在哪里了解更多?
对这一增强感兴趣的人:
- Kubernetes GitHub Issue #131216——详细的技术分析和示例,包括关于选择上述公式的讨论与理由。
- KEP-2254:cgroup v2——Kubernetes 中最初的 cgroup v2 实现。
- Kubernetes cgroup 文档——当前资源管理指南。
我如何参与?
如果你有兴趣参与 Kubernetes 节点级功能,请加入 Kubernetes Node Special Interest Group。我们始终欢迎新的贡献者,以及关于资源管理挑战的多元视角。
- ← 上一篇
- 下一篇 →