中文内容
编者按:本文是 Nemotron Labs 博客系列的一部分,该系列探讨最新的开放模型、数据集和训练技术如何帮助企业在 NVIDIA 平台上构建专用 AI 系统和应用。每篇文章都会重点介绍使用开放技术栈在生产环境中交付实际价值的实用方式——从透明的研究副驾驶到可扩展的 AI 智能体。
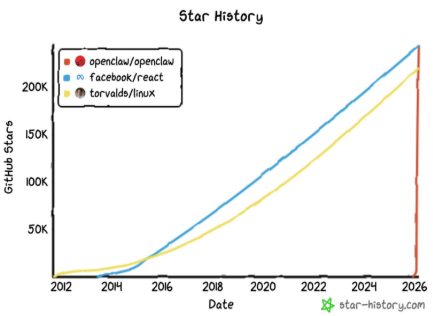
到 2026 年初,开源项目 OpenClaw 已成为一种现象。1 月,随着开发者兴趣激增,它在 GitHub 上的星标数突破 100,000。社区仪表板和流量分析显示,单周访问者超过 200 万。到 3 月,OpenClaw 的星标数超过 250,000——在短短 60 天内超越 React,成为 GitHub 上星标数最多的软件项目。
OpenClaw 由 Peter Steinberger 创建,是一款自托管、持久运行的 AI 助手,旨在本地或私有服务器上运行。该项目因其易用性和不受限制的自主性而受到关注:用户可以在本地部署 AI 模型,而无需依赖云基础设施或外部应用程序编程接口(API)。
如今,大多数 AI 智能体由提示触发,完成一项已定义的任务后便停止运行。长期运行的自主智能体,或称“claw”,则以不同方式工作。这类智能体会在后台持续运行,自行完成任务,并且只在需要人类决策时才浮现出来。它们按心跳机制运行:以固定间隔检查任务列表,评估哪些事项需要采取行动,然后要么执行操作,要么等待下一个周期。
OpenClaw 的快速采用也引发了争议。安全研究人员对自托管 AI 工具如何管理敏感数据、身份验证和模型更新提出了担忧。其他人则质疑,本地部署是否会让用户面临新的风险——从未打补丁的服务器实例到社区分支中的恶意贡献。随着贡献者和维护者努力解决这些问题,OpenClaw 的兴起促使整个 AI 生态系统围绕开放性、隐私和安全之间的权衡展开了更广泛的讨论。
为帮助提升 OpenClaw 项目的安全性和稳健性,NVIDIA 正与 Steinberger 以及 OpenClaw 开发者社区合作,以解决潜在漏洞,相关内容详见 OpenClaw 最近的一篇博客文章。
NVIDIA 贡献了专注于改进模型隔离、更好地管理本地数据访问以及强化社区代码贡献验证流程的代码和指导。其目标是通过以开放、透明的方式贡献其安全与系统专业能力来支持该项目的发展势头,在加强社区工作的同时保留 OpenClaw 的独立治理。
为帮助企业更安全地使用长时间运行的智能体,NVIDIA 还推出了 NVIDIA NemoClaw,这是一个参考实现,可通过单个命令安装 OpenClaw、NVIDIA OpenShell 安全运行时以及 NVIDIA Nemotron 开放模型,并在网络、数据访问和安全方面采用强化的默认设置。NemoClaw 可作为组织更安全地部署 claws 的蓝图。
推理需求随着每一波 AI 浪潮成倍增长
AI 已经历四个阶段,而且每个阶段之间的间隔正在缩短。预测式 AI 花了数年时间才成为主流。生成式 AI 发展得更快。推理式 AI 到来得更快。自主式 AI——OpenClaw 所代表的浪潮——正在设定更快的步伐。
每一波浪潮中复合增长的是推理需求。生成式 AI 相比预测式 AI 增加了 token 使用量。推理型 AI 又将其提高了 100 倍。自主智能体会持续运行并跨越较长时间跨度执行操作,使推理需求相比推理型 AI 再增加 1,000 倍。每一波浪潮都会成倍增加所需计算量。
token 使用量的增长正在使组织的生产力提升数个数量级。例如,长时间运行的智能体可以帮助研究人员在夜间推进一个问题,跨数千种配置迭代设计,或监控系统并仅呈现需要人类判断的异常情况——从而让研究人员在工作日中腾出时间处理更高价值的任务。
选择工具:何时部署“Claw”
虽然生成式 AI 已成为按需任务的常用工具,但在某些特定场景下,Claw 持续存在的“心跳”会带来明显优势。判断何时从标准的基于提示词的 AI 转向长时间运行的智能体,通常取决于工作流程的性质:
- 从“按需”到“始终在线”:标准模型非常适合即时的、由人类触发的查询,而 claws 通常更适合需要持续后台监控或定期系统检查、且无需手动启动的任务。
- 管理高迭代循环:对于复杂问题,例如测试数千种化学组合或模拟基础设施压力测试,claw 可以管理庞大的迭代量,否则这些迭代可能会因人工干预而成为瓶颈。
- 从建议转向行动:在许多工作流中,标准 AI 用于提供信息或草稿。当目标是让 AI 进入执行阶段——与 API 交互、更新数据库或在较长时间范围内管理文件时,通常会考虑使用 claw。
- 资源优化:对于大规模、token 密集型推理任务,在 NVIDIA DGX Spark 个人 AI 超级计算机等专用硬件上部署本地 claw,相比高频云 API 调用,可以带来更可预测的成本和数据隐私。
组织如何使用长时间运行的自主智能体?
长时间运行的自主智能体的实际应用横跨各类职能和行业。
在金融服务领域,智能体持续监控交易系统和监管信息源,在晨间审查前标记重大事件。在药物发现领域,智能体扫描新的科学文献,提取相关发现,并在无需研究人员干预的情况下实时更新内部数据库——这一流程过去需要数周时间。
在工程和制造领域,智能体通过测试数千种参数组合、对结果进行排序并标记值得检查的配置来加快问题分析——而这一切都可以在一夜之间完成。
在 IT 运维中,代理能够诊断基础设施事件,应用已知的修复措施,并且只将新颖问题上报——将平均解决时间从数小时压缩到数分钟。在 ServiceNow,利用 Apriel 和 NVIDIA Nemotron 模型的 AI 专家可以自主解决 90% 的工单。
企业如何负责任地部署自主代理?
自主代理会直接动手执行任务。它们可以发送通信、写入文件、调用 API 并更新实时系统。当代理执行错误操作时,会产生真实后果。从一开始就建立正确的问责框架至关重要,在生产环境中部署自主代理的组织必须将治理视为首要要求。
组织需要了解其代理正在做什么,检查它们在每一步的推理,审计它们的操作,并在需要时进行干预。
负责任地部署自主智能体的组织正聚焦于三项优先事项:
- 开放、可审计的框架:NemoClaw 基于 OpenClaw 的 MIT 许可代码库构建,这意味着组织拥有完整的智能体运行框架。他们可以阅读、分叉并修改智能体构建和部署方式的每一层。这种透明性使团队能够在代码层面理解和控制系统。在本地运行 NVIDIA Nemotron 等开源模型,可将敏感工作负载(包括患者记录、法律文件、金融交易和专有研究)保留在组织自身环境中,确保追踪数据始终由组织掌控。
- 保护运行时环境:NemoClaw 在 OpenShell 内运行智能体,OpenShell 是一个沙盒环境,可精确定义智能体能做什么和不能做什么,并从一开始就强制执行明确的权限边界。
- 本地计算:NVIDIA DGX Spark 超级计算机以桌边式外形规格提供数据中心级 GPU 性能,专为始终在线的连续本地推理而构建,支持本地模型托管,并使数据留在组织环境内。NVIDIA DGX Station 系统可扩展这种能力,支持团队在复杂、持续的工作负载中同时运行多个智能体。
那些正在定义自主智能体在实践中能做什么的组织,正在积累某种有价值的东西:数月的实时运营经验、通过真实工作负载形成的治理框架,以及已经吸收了机构背景、因而真正有用的智能体。这一基础只会随着时间推移而不断深化。
开始使用 NVIDIA NemoClaw
查看分步教程,了解如何在 NVIDIA DGX Spark 上使用 NemoClaw 构建更安全的 AI 智能体。探索 NemoClaw 如何通过单个命令部署更安全、始终在线的 AI 助手。
试用 GitHub 上提供的 NemoClaw,并加入 Discord 上的开发者社区,与大家一起在 DGX Spark 上使用 NVIDIA Nemotron 3 Super 和 Telegram 构建基于 NemoClaw 的应用。
订阅 NVIDIA AI 新闻、加入社区,并在 LinkedIn、Instagram、X 和 Facebook 上关注 NVIDIA AI,随时了解 agentic AI、NVIDIA Nemotron 等最新动态。
探索自定进度的视频教程和直播。