中文内容

概览
- 当今的关键服务和应用通常具有很高的并发性,会使用数百个线程。它们也在大规模内存环境下运行,通常达到数百 GB,尤其是在使用大型语言模型时。
- mimalloc 是一个开源、现代、可扩展的内存分配器,可直接替代 malloc 和 free。它相对小巧(约 1.2 万行代码),内部数据结构清晰,并且易于构建和集成到其他项目中。它提供有界的最坏情况分配时间(不超过操作系统原语)、有界的空间开销、低内部碎片率,并且几乎完全依靠原子操作来实现最小竞争。
- mimalloc 可在 GitHub(在新标签页中打开)上获取,并拥有超过 1.2 万颗星。
正文:mimalloc
在 Microsoft Research(MSR)的 RiSE 小组,我们开展形式化方法、编程语言和软件工程(包括新兴的智能体系统)方面的基础研究,尤其关注那些可被证明为正确、安全且高性能的系统。mimalloc 内存分配器最初于 2020 年设计,作为 RiSE 开发的最先进 Lean(在新标签页中打开)和 Koka(在新标签页中打开)编程语言的快速分配器,这两种语言都采用了新颖的编译器引导引用计数(见 Perceus)。
mimalloc 的可扩展设计也被证明非常适用于 Microsoft 的大型服务。通过与产品团队的密切合作,mimalloc 显著改善了 Bing 等服务的响应时间。如今,mimalloc 已广泛用于 Microsoft 内外的大型服务和应用程序。它是 NoGIL CPython 3.13+ 的分配器,已集成到 Unreal Engine 中,并用于 Death Stranding 等游戏。该项目在 GitHub 上开源,拥有超过 1.2 万颗星;仅其 Rust 封装器每天的下载量就超过 10 万次。
mimalloc 在广泛的场景中都很有效;从 Koka 或 Lean 这样的小规模应用,到内存占用超过 500 GiB、拥有数百个线程的大型服务。
尽管具备这样的适用范围,该代码库仍然很紧凑,约有 1.2 万行 C 代码。mimalloc 反映了其研究出身,强调清晰的内部数据结构和强不变量,因此相比许多工业级分配器,更容易理解和推理。正如 Fred Brooks 在其著名著作 The Mythical Man-Month 中所说:“把你的流程图给我看,却把你的表藏起来,我仍会感到困惑。把你的表给我看,我就不需要你的流程图了;一切都会很明显。”
因此,mimalloc 已被移植到许多平台——Windows、macOS、Linux、FreeBSD、NetBSD、DragonFly 以及各种游戏主机——并且易于构建和集成到其他项目中。例如,清晰的数据结构使 Sam Gross 等人能够采用 mimalloc 作为 NoGIL CPython 的并发分配器。该设计也使得在其之上实现循环垃圾回收相对直接。
快速路径
与其他可扩展分配器(如 tcmalloc 和 jemalloc)一样,mimalloc 的一个核心设计原则是每个线程维护自己的线程局部堆,我们称之为“theap”。每个 theap 拥有一组 mimalloc“页”,这些页通常为 64 KiB。每个 mimalloc 页包含固定大小的块,并按大小类别组织,以减少内部碎片。通过为每个线程提供自己的 theap 和一组 mimalloc 页,内存分配和释放通常无需同步即可进行。只有当一个线程释放由另一个线程分配的块时,才需要原子操作。
此外,在实践中,大多数分配都相当小,通常小于 1 KiB。对于这类小型分配,mimalloc 提供了一条快速路径,其中主分配函数如下所示:
void* mi_malloc( size_t size )
{
mi_theap_t* const theap = mi_get_thread_local_theap();
if (size > MI_MAX_SMALL_SIZE) return mi_malloc_generic(theap,size); // slow generic path
const size_t index = (size + sizeof(void*))/sizeof(void*); // round size
mi_page_t* const page = theap->small_pages[index];
mi_block_t* const block = page->free; // head of free list
if (block == NULL) return mi_malloc_generic(theap,size); // slow generic path
page->free = block->next; // pop free list
page->used++;
return block;
}通过使用线程局部的 theap,我们不需要原子操作或线程同步。我们还尽量减少分支数量。具体而言,线程局部的 theap 永远不会是 NULL,并且我们用一个特殊的空 theap 对其进行初始化,其中所有页面都是空的。这样,我们就不需要单独检查 theap 是否为 NULL。类似地,small_pages 数组中的指针也永远不会是 NULL,并且我们再次使用特殊的空页面(其 page->free==NULL)来避免单独检查。最后,页面使用空闲列表而不是单独的 bump pointer 进行初始化,从而避免特殊情况,并通过简单地从空闲列表中弹出块来实现分配。在 x64 上,这段代码现在会转换为少量指令,并且只有两个不常见的分支:
mi_malloc:
movq %rdi, %rsi ; rsi = size
movq _mi_theap_default@GOTTPOFF(%rip), %rax
movq %fs:(%rax), %rdi ; rdi = thread local theap
cmpq $1024, %rsi ; size > MI_MAX_SMALL_SIZE?
ja .LBB0_generic
leaq 7(%rsi), %rax ; round to sizeof(void*)
andq $-8, %rax
movq 232(%rdi,%rax), %rcx ; rcx = heap->small_pages[index]
movq 8(%rcx), %rax ; block = rax = page->free
testq %rax, %rax ; block == NULL?
je .LBB0_generic
movq (%rax), %rdx ; page->free = block->next
movq %rdx, 8(%rcx)
incw 16(%rcx) ; page->used++
retq
.LBB0_generic:
jmp _mi_malloc_generic@PLT ; tailcall
类似地,mimalloc 为释放块提供了一条快速路径。在实践中,大多数块都是由分配该块的同一线程释放的。我们可以通过检查当前线程 ID 是否与相应 mimalloc 页面中存储的线程 ID 匹配来优化这种情况。如果匹配,我们就可以直接将该块推入页面的空闲列表,而无需原子操作或锁:
void mi_free(void* p)
{
mi_page_t* const page = mi_ptr_page(p); // get the page meta-data that contains p
if (page==NULL) return;
if (mi_thread_id() == page->thread_id) { // do we own this page?
mi_block_t* const block = (mi_block_t*)p;
block->next = page->local_free; // push on the `local_free` list
page->local_free = block;
if (--page->used == 0) mi_page_free(page); // is the entire page free?
}
else {
mi_free_cross_thread(page, p); // free in a page owned by another thread
}
} 最新的 mimalloc v3 中的 mi_ptr_page 函数使用按需分配的整块内存映射来检索页面元数据。在早期版本中,这通过对齐技巧实现得更快。然而,在实践中,当全局覆盖 free 时,无效指针经常会被传递给 mi_free。
使用单独的映射可以高效检测这类情况,并在指针无效时返回 NULL。特别是,mi_ptr_page(NULL) == NULL,这通过仅测试页面是否为 NULL 来避免额外的分支。此外,used count 用于高效检测页面中的所有块何时都已被释放。
当一个块跨线程释放时,我们会进入 mi_free_cross_thread 函数——这是第一个需要原子操作的路径:
void mi_free_cross_thread(mi_page_t* page, mi_block_t* block)
{
mi_block_t* tfree = mi_atomic_load(&page->thread_free); // head of the thread free list
do {
block->next = tfree; // push our block in front
} while (!mi_atomic_compare_and_swap(&page->thread_free, &tfree /*expect*/, block /*new*/))
}可以通过将该块推入页面的 thread-free list 来释放该块。由于这是多线程操作,因此需要一次原子 compare-and-swap 操作来以原子方式推入该块。尽管如此,在现代硬件上,此类操作在无竞争时是高效的,因为它们的操作与缓存一致性协议(MOESI)集成在一起。
空闲列表混乱
每个页有三个空闲列表:用于分配的空闲列表、用于已释放块的 local_free 列表,以及用于跨线程释放的块的 thread_free(原子)列表。这保证了在固定次数的分配之后,空闲列表会被耗尽,从而确保我们偶尔会走较慢的通用分配路径。这也用于清理空闲列表,即把线程本地和本地空闲列表移回主空闲列表。(注意:实际实现需要更加谨慎,以处理所属线程不再进行分配或长时间被阻塞的情况)。
因此,mimalloc 在每个(64 KiB)mimalloc 页上有三个空闲列表,实际上这意味着一个程序很容易拥有数千个空闲列表。这对 mimalloc 的可扩展性和缓存局部性至关重要。

对于这种设计,我们从随机化算法中汲取了灵感。例如,为了平衡一棵二叉树,我们可以使用基于权重或深度的智能策略,并执行特定的旋转来保持其平衡。这类算法通常相当复杂。然而,我们也可以简化这一过程,在插入时随机决定分裂方式,而纯粹凭借概率,我们最终也能得到足够平衡的树。
类似地,许多多线程分配器依赖复杂的并发数据结构来同步对共享空闲列表的访问。相比之下,mimalloc 使用按页划分的线程空闲列表,任何线程都可以通过简单的原子比较并交换操作推入一个块。由于存在数千个这样的列表,多个线程同时将块释放到同一页的概率很低。因此,大多数推入操作都是无竞争的原子更新。通过按每个 64 KiB 的 mimalloc 页组织这些列表,可以改善缓存局部性,因为分配往往会一直停留在同一页内,直到该页填满,而不受其他页中已释放对象的影响。
相比之下,考虑一种每个线程或进程只有一个空闲列表的设计。在分配新结构的同时释放相同大小的对象时——这是树转换等工作负载中的常见模式——分配可能会复用最近释放的、散布在整个内存中的块,从而导致局部性降低。
线程之间的共享
在线程之间的可扩展性与高效内存共享之间存在一种根本性张力。为了实现最佳扩展性,我们会让每个线程独占其自己的页面,以尽量减少任何线程同步。另一方面,这可能导致内存浪费:假设一个线程有大量空闲块,而另一个线程需要分配该大小的块——如果无法共享或窃取这些页面,我们就需要改为分配新的内存。在另一个极端,我们可以让所有线程通过一把锁共享所有页面:这样内存使用是最优的,但我们不再具备可扩展性。以下基准测试结果说明了这种张力:
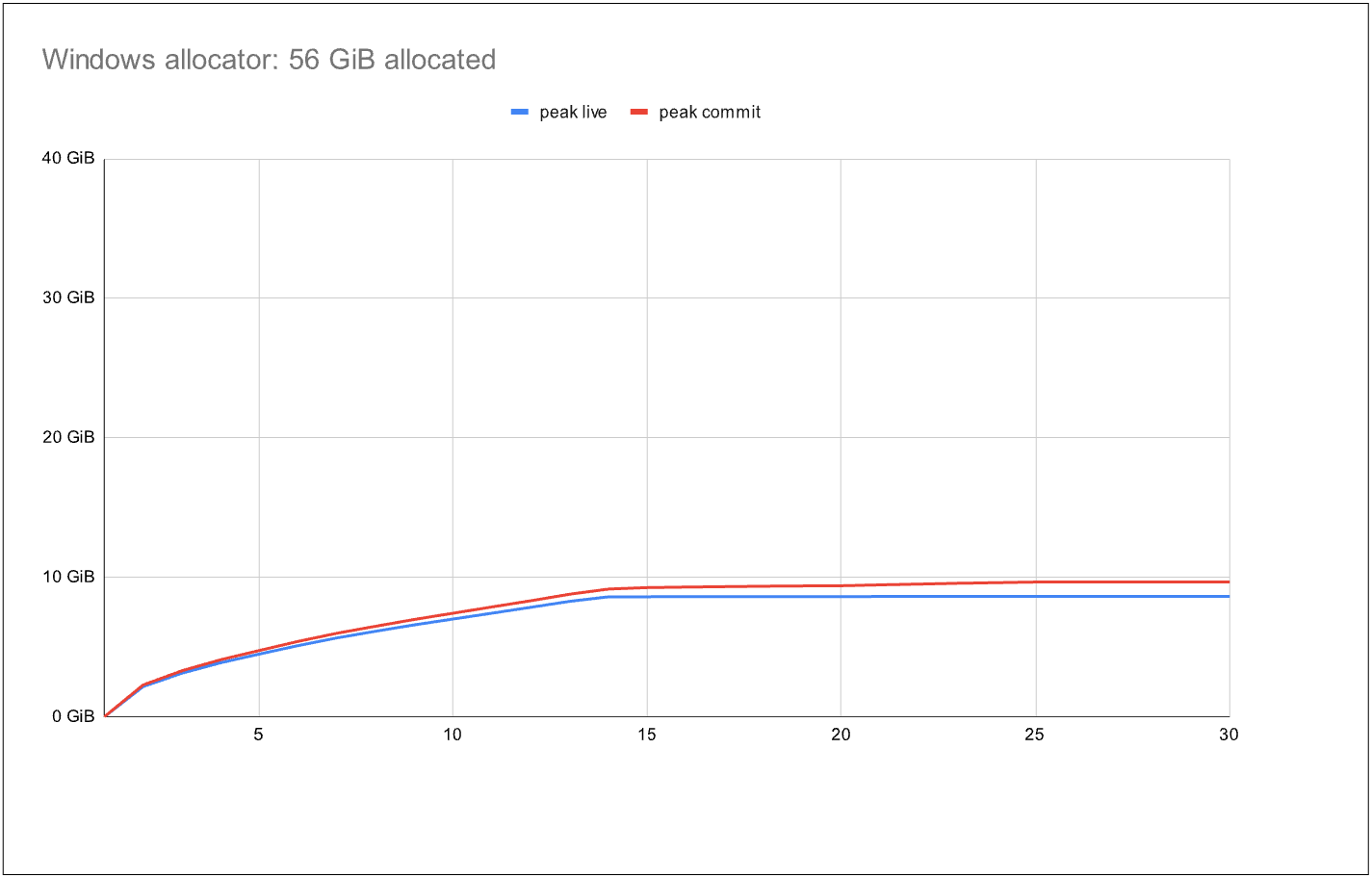
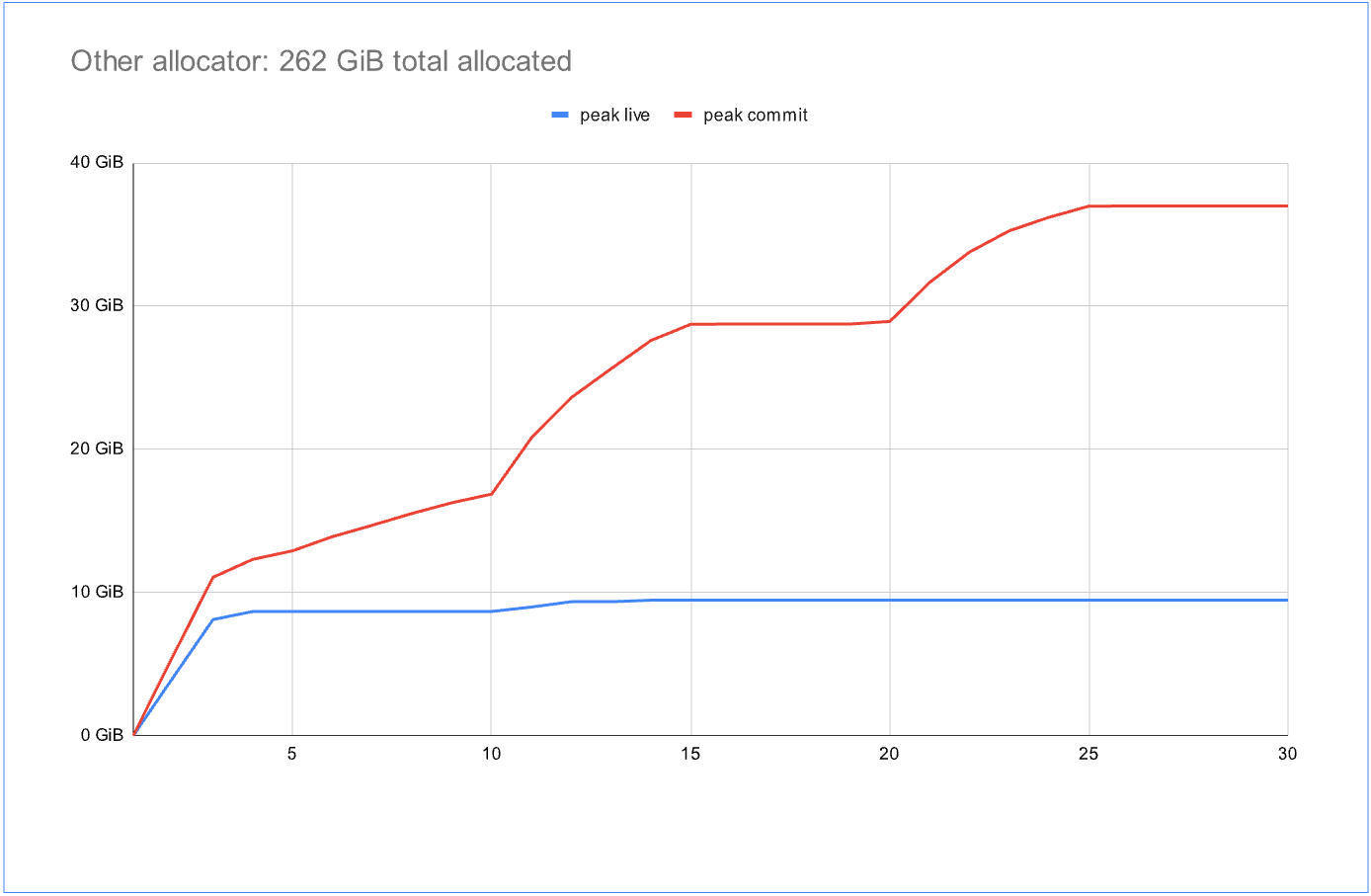
该基准测试使用 Windows 线程池,在固定时长内运行许多任务,约有 800 个活动线程。这些任务在分配、释放和短暂阻塞期间交替进行,模拟典型的服务工作负载。在图中,蓝线表示总实时数据量,而红线表示分配器提交的总内存。理想情况是红线尽可能接近蓝线。第一张图几乎就是这种情况,它使用的是标准系统分配器:到最后,提交内存仅比实时数据多 1.1 倍——这是一个出色的结果!不过,在整个基准测试期间,它总共只分配了 56 GiB 数据。
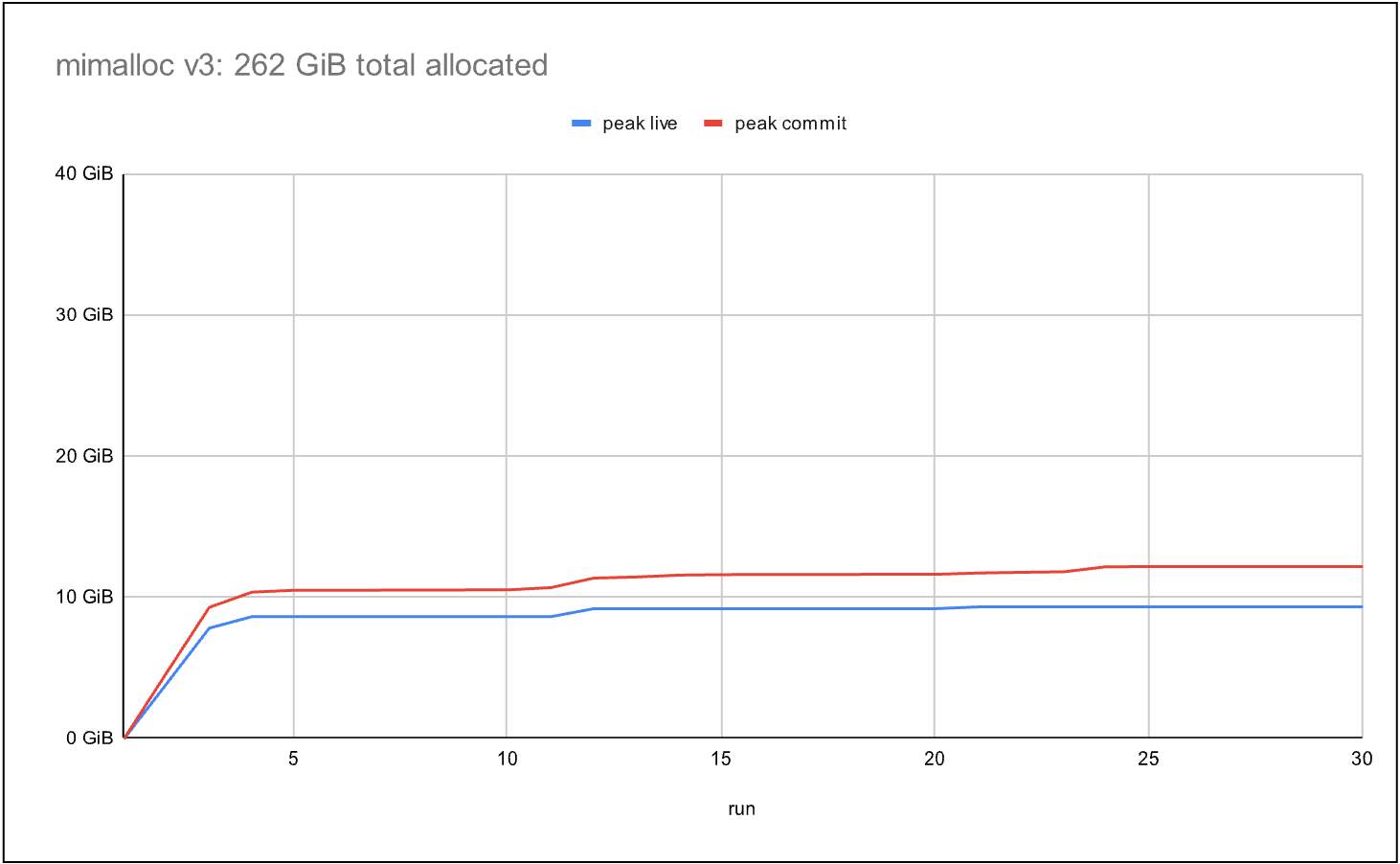
与第二张图中的另一个高并发分配器形成对比,后者在基准测试期间能够分配 262 GiB——几乎是前者的 4 倍。然而,它提交的内存也是实时数据的 4 倍。在内存占用更大的真实工作负载中,这样的比例很快就会变得不可接受。在这里我们看到,标准分配器的扩展性不如它,但表现出了更好的跨线程内存共享能力。
最后一张图显示的是最新的 mimalloc 分配器。与第二个分配器一样,它在基准测试期间分配了 262 GiB,同时将提交内存减少到实时数据的 1.3 倍,从而实现了可扩展性以及线程之间高效的内存共享。类似于现代线程池实现中的工作窃取,mimalloc 使用了一种“页面窃取”技术,允许线程在无需昂贵的跨线程同步的情况下取得页面的所有权。
这些改进是在与 Microsoft 的 Azure Cosmos DB 团队密切合作中完成的。精确的描述超出了本博客的范围,但我们很快会发布一份技术报告——敬请关注。
在新标签页中打开


