中文内容
今天,我们很高兴分享 Gemini 2.5 模型家族的全面更新:
- Gemini 2.5 Pro 已正式可用并进入稳定版(与 06-05 预览版相比无变化)
- Gemini 2.5 Flash 已正式可用并进入稳定版(与 05-20 预览版相比无变化,价格更新见下文)
- Gemini 2.5 Flash-Lite 现已提供预览版
Gemini 2.5 模型是思考型模型,能够在回应前通过内部思路进行推理,从而提升性能并提高准确性。每个模型都可以控制思考预算,使开发者能够选择模型在生成回复前何时以及进行多少“思考”。
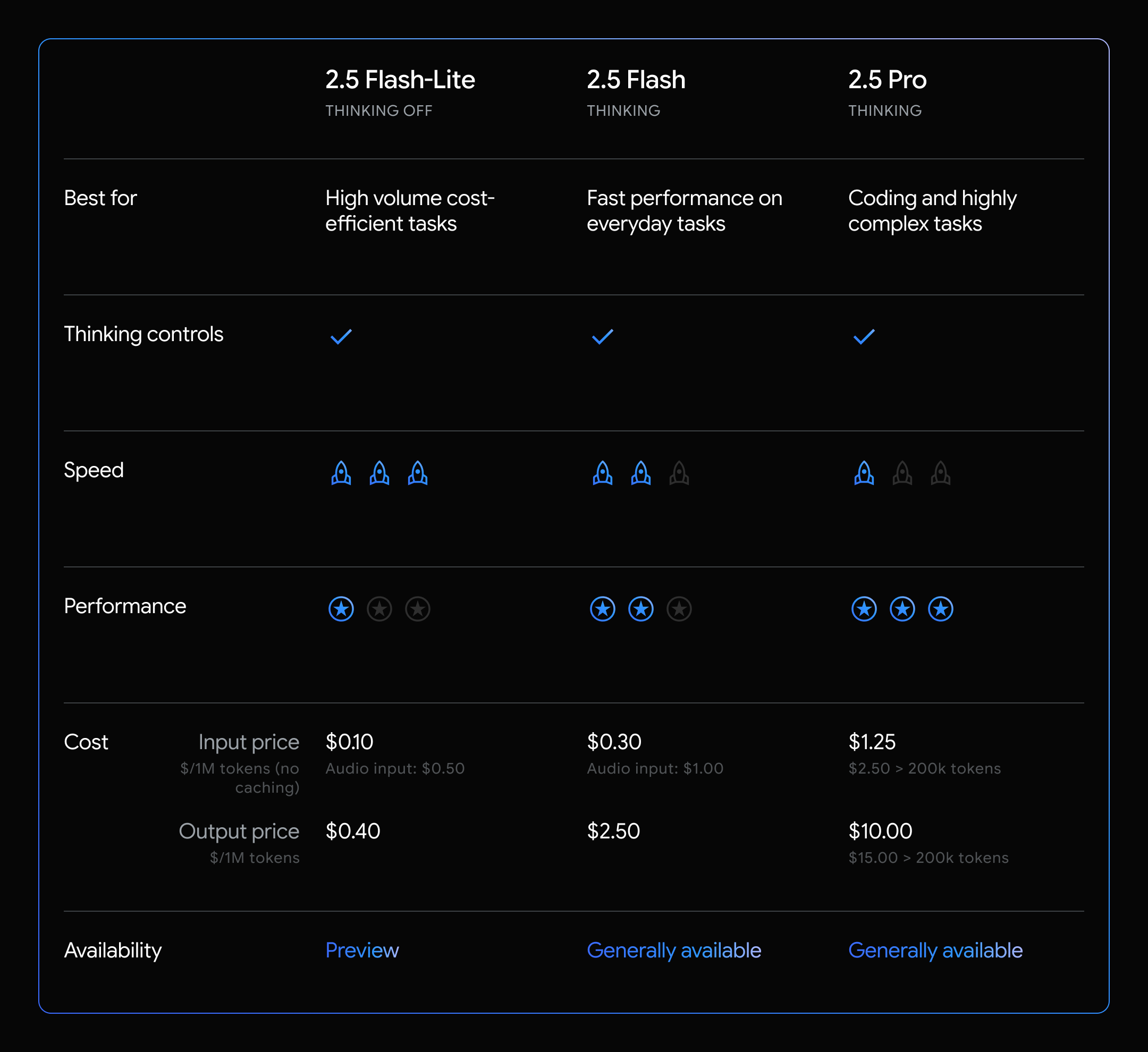
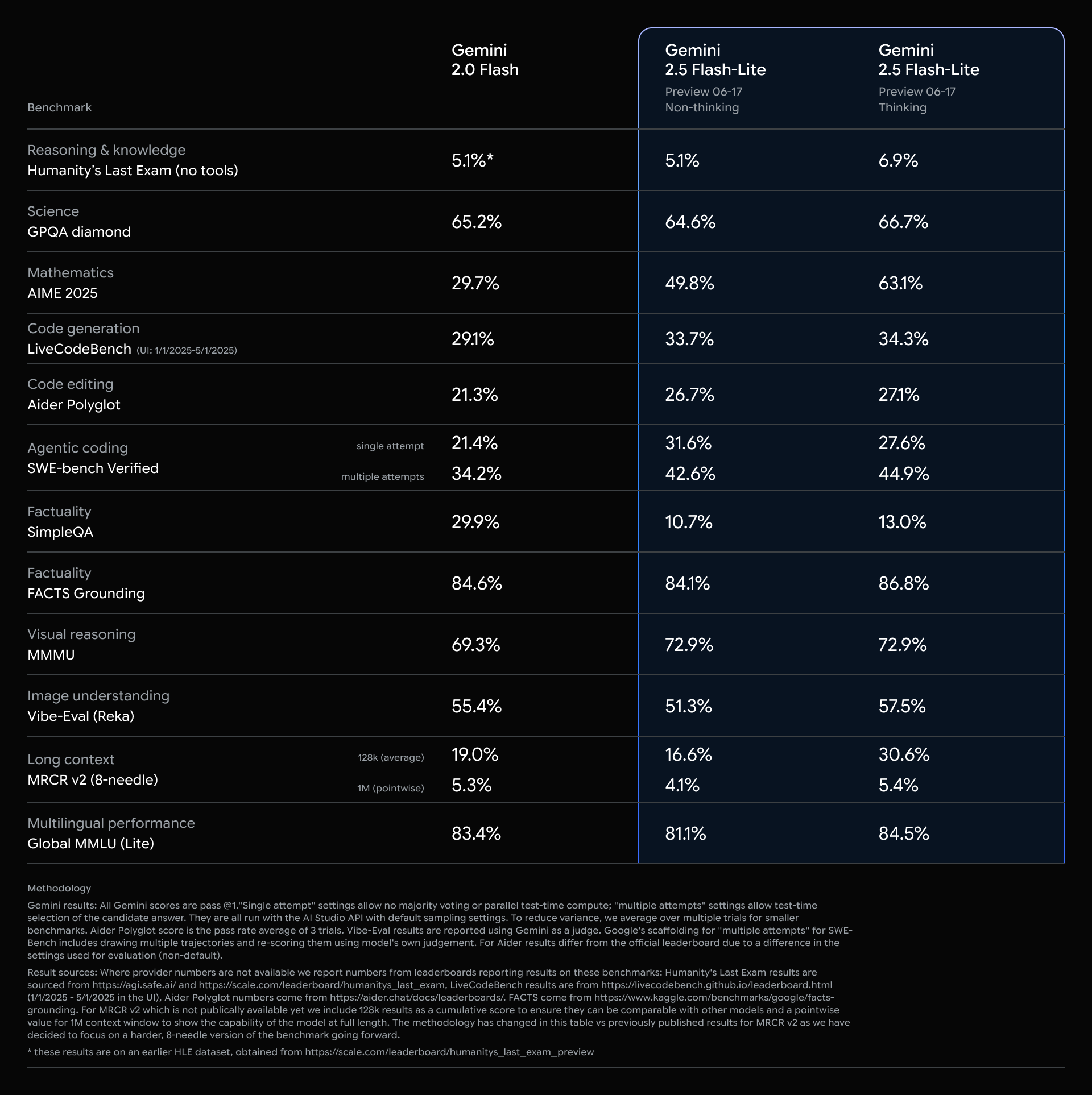
推出 Gemini 2.5 Flash-Lite
今天,我们推出 2.5 Flash-Lite 预览版,它在 2.5 模型家族中具备最低延迟和最低成本。它被设计为我们此前 1.5 和 2.0 Flash 模型的高性价比升级版本。它还在大多数评测中提供更好的性能,并降低首个 token 生成时间,同时实现更高的每秒 token 解码量。该模型非常适合分类或大规模摘要等高吞吐量任务。
Gemini 2.5 Flash-Lite 是一种推理模型,允许通过 API 参数动态控制思考预算。由于 Flash-Lite 针对成本和速度进行了优化,与我们的其他模型不同,“思考”默认关闭。除函数调用外,2.5 Flash-Lite 还支持我们所有原生工具,例如 Grounding with Google Search、Code Execution 和 URL Context。
Gemini 2.5 Flash 与价格更新
过去一年,我们的研究团队持续推动 Flash 模型系列的帕累托前沿。当 2.5 Flash 最初发布时,我们尚未最终确定 2.5 Flash-Lite 的能力。我们还以“思考”和“非思考价格”推出,这导致开发者感到困惑。随着 Gemini 2.5 Flash 稳定版推出(即我们在 Google I/O 提供的同一个 05-20 模型预览版),并考虑到 2.5 Flash 的出色性能,我们正在更新 2.5 Flash 的价格:
- 每 100 万输入 token 0.30 美元(*从输入 0.15 美元上调)
- 每 100 万输出 token 2.50 美元(*从输出 3.50 美元下调)
- 我们取消了思考与非思考之间的价格差异
- 无论输入 token 大小如何,我们都保留单一价格层级
虽然我们努力在预览版和稳定版之间保持一致定价,以尽量减少干扰,但这是一项具体调整,反映了 Flash 的卓越价值,仍提供当前最佳的单位智能成本。
借助 Gemini 2.5 Flash-Lite,我们现在为对成本和延迟敏感、且对模型智能要求较低的用例提供了成本更低的选项(无论是否启用思考)。

如果你正在使用 Gemini 2.5 Flash Preview 04-17,现有预览版价格将在其计划于 2025 年 7 月 15 日弃用前继续有效,届时该模型端点将被关闭。你可以迁移到正式可用模型“gemini-2.5-flash”,或切换到 2.5 Flash-Lite Preview 作为更低成本选项。
Gemini 2.5 Pro 持续增长
Gemini 2.5 Pro 的增长和需求持续保持在我们迄今所有模型中最陡峭的水平。为了让更多客户在生产环境中基于该模型构建,我们将该模型的 06-05 版本设为稳定版,并保持与此前相同的帕累托前沿价格点。
我们预计,在需要最高智能和最多能力的场景中,Pro 将表现突出,例如编码和代理式任务。Gemini 2.5 Pro 是许多最受喜爱的开发者工具的核心。

如果你正在使用 2.5 Pro Preview 05-06,该模型将持续可用至 2025 年 6 月 19 日,之后将被关闭。如果你正在使用 2.5 Pro Preview 06-05,只需将模型字符串更新为“gemini-2.5-pro”即可。
我们迫不及待想看到更多领域受益于 2.5 Pro 的智能,并期待在不久的将来分享更多关于超越 Pro 扩展的信息。
- 正文:Gemini
- 正文:AI
- 公告
- 正文:Gemini 2.5 Flash-Lite
- AI 模型
- 正文:Gemini 2.5 Pro
- 正文:Vertex AI
- 开发者工具
- 正文:Gemini 2.5
- 正文:Gemini 2.5 Flash
- 机器学习
- 正文:Google AI Studio





