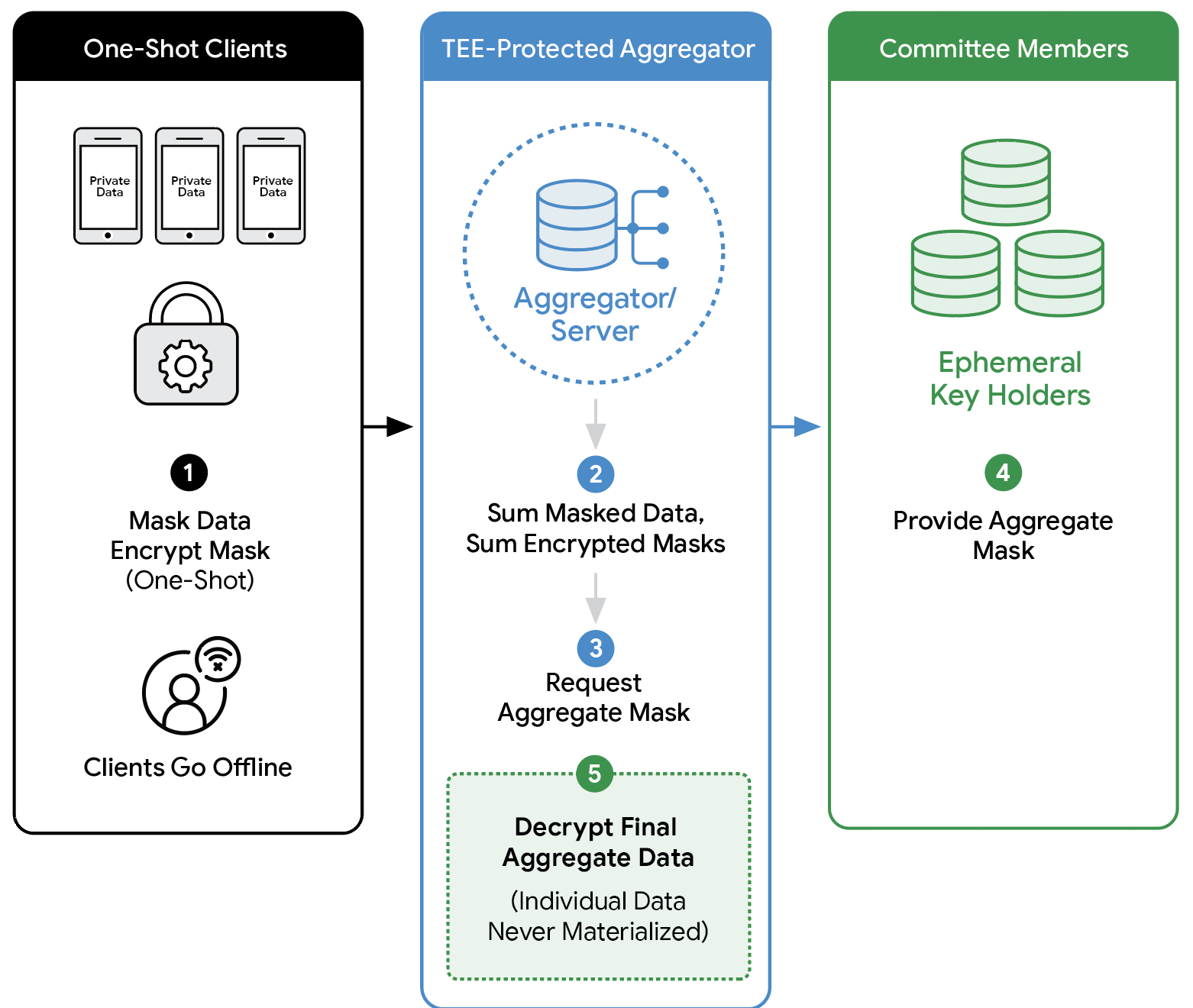
中文内容

VaultGemma:全球最强大的差分隐私 LLM
2025 年 9 月 12 日
Amer Sinha,软件工程师,Ryan McKenna,研究科学家,Google Research
我们介绍 VaultGemma,这是从零开始采用差分隐私训练的最强大模型。
快速链接
- 论文
- 正文:Hugging Face
- 正文:Kaggle
- 技术报告
随着 AI 越来越融入我们的生活,以隐私为核心来构建 AI 已成为该领域的关键前沿。差分隐私(DP)通过添加经过校准的噪声来防止记忆,提供了一种数学上可靠的解决方案。然而,将 DP 应用于 LLM 会带来权衡。理解这些权衡至关重要。应用 DP 噪声会改变传统的缩放定律——即描述性能动态的规则——因为它会降低训练稳定性(模型在不经历损失尖峰或发散等灾难性事件的情况下持续学习的能力),并显著增加批量大小(同时发送给模型进行处理的一组训练样本)和计算成本。
我们与 Google DeepMind 合作开展的新研究《Scaling Laws for Differentially Private Language Models》建立了能够准确刻画这些复杂性的定律,全面呈现了计算、隐私与效用之间的权衡。在这项研究的指导下,我们很高兴推出 VaultGemma,这是从零开始使用差分隐私训练的最大(10 亿参数)开放模型。我们将在 Hugging Face 和 Kaggle 上发布权重,并同时发布一份技术报告,以推动下一代私有 AI 的发展。
理解缩放定律
通过精心设计的实验方法,我们旨在量化在 DP 训练背景下增加模型规模、批量大小和迭代次数所带来的收益。我们的工作需要做出一些简化假设,以应对可能考虑尝试的组合数量呈指数级增长的问题。我们假设,模型的学习效果主要取决于“噪声-批量比”,即将我们为保护隐私而添加的随机噪声量与用于训练的数据组(批量)大小进行比较。这一假设之所以成立,是因为我们添加的隐私噪声远大于数据采样所产生的任何自然随机性。
为了建立 DP 缩放定律,我们开展了一组全面的实验,以评估不同模型规模和噪声-批量比下的性能。所得的经验数据,再结合其他变量之间已知的确定性关系,使我们能够回答各种有趣的、类似缩放定律的问题,例如:“在给定计算预算、隐私预算和数据预算的情况下,什么训练配置最优,能够实现尽可能低的训练损失?”

我们的 DP 缩放定律结构。我们证明,预测损失可以主要使用模型规模、迭代次数和噪声-批量比来准确建模,从而简化计算、隐私和数据预算之间复杂的相互作用。
主要发现:强大的协同效应
在深入探讨完整的缩放定律之前,有必要从隐私核算的角度理解计算预算、隐私预算和数据预算之间的动态关系与协同效应——也就是说,理解这些因素如何在固定模型规模和迭代次数下影响噪声-批量比。进行这项分析的成本要低得多,因为它不需要任何模型训练,但仍能得出许多有用见解。例如,单独增加隐私预算会带来递减收益,除非同时相应增加计算预算(FLOPs)或数据预算(tokens)。
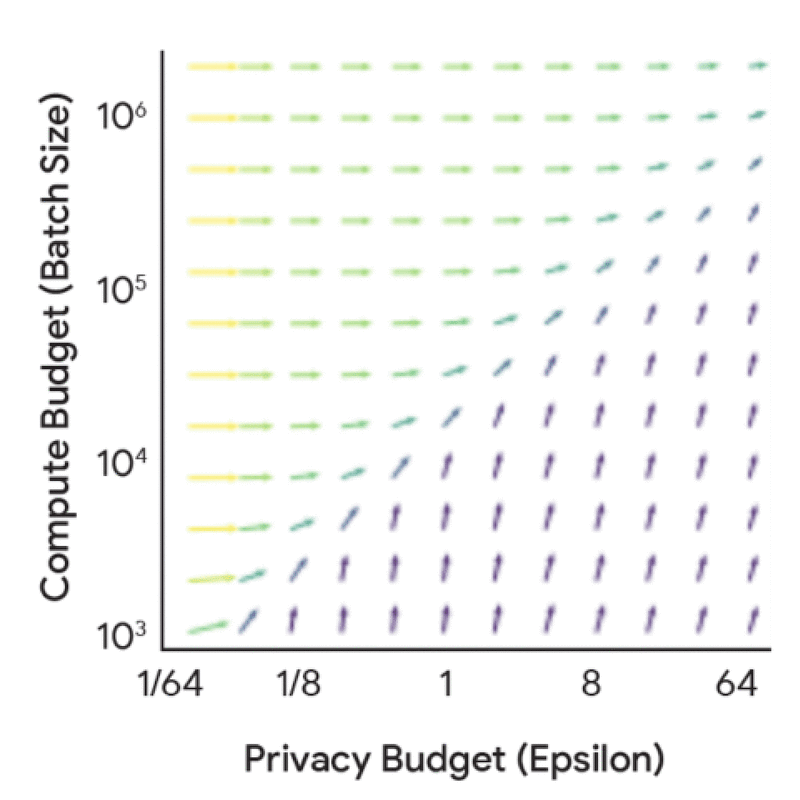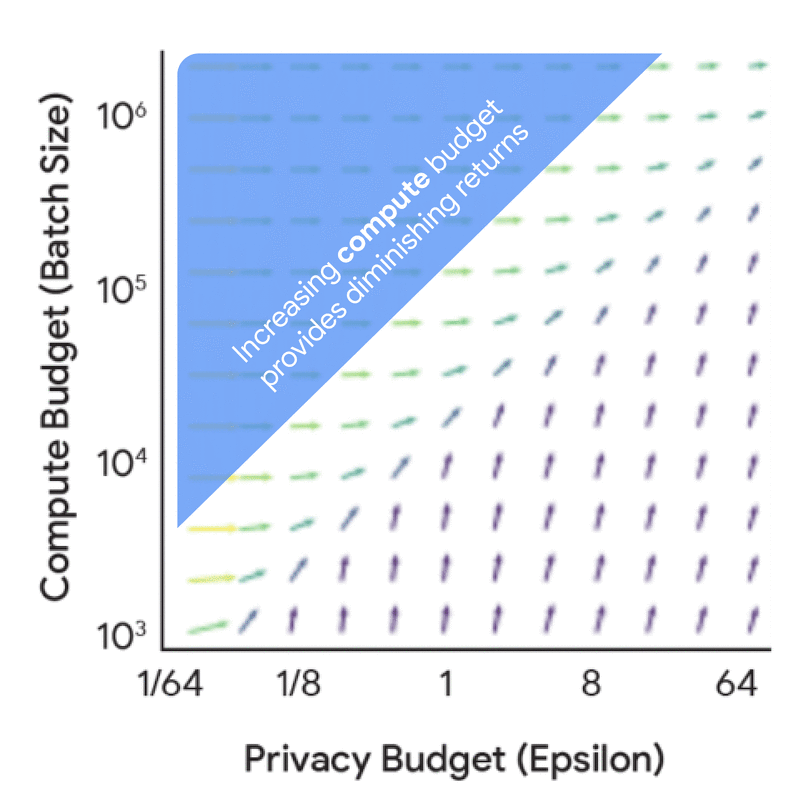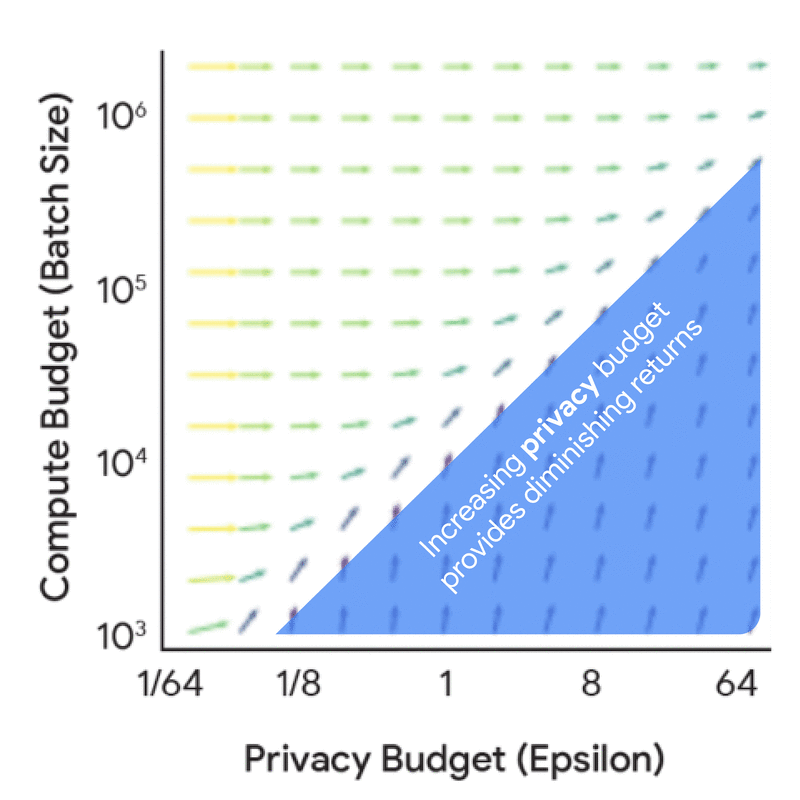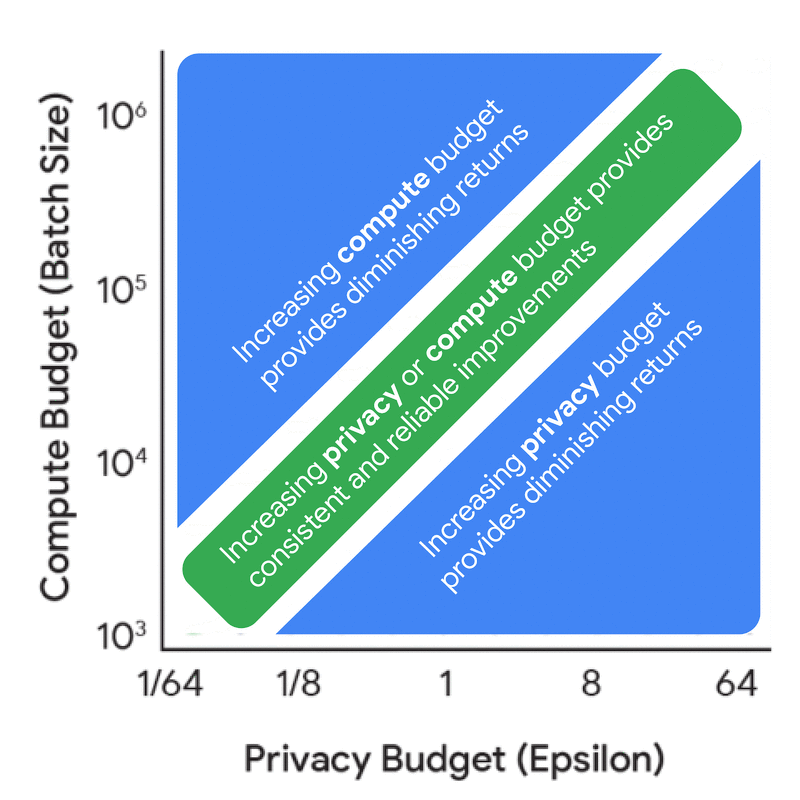
增加隐私预算(epsilon)和计算预算(批量大小)对噪声-批量比影响的边际收益。
为了进一步探索这种协同效应,下面的可视化展示了在不同约束条件下最优训练配置如何变化。随着隐私预算和计算预算的变化,请注意建议如何在投资更大模型与使用更大批量大小或更多迭代进行训练之间转变。
不同数据/隐私/计算预算设置下的预测训练损失,并按迭代次数、批量大小和模型规模进行了进一步的详细分解。这些图既展示了不同预算设置下可达到的最小损失,也展示了最优超参数配置。
这些数据为从业者提供了大量有用的洞见。虽然论文中报告了所有洞见,但一个关键发现是:与不使用 DP 时相比,应训练一个小得多的模型,并使用大得多的批量大小。鉴于大批量大小的重要性,这一总体洞见对 DP 专家而言应当并不意外。尽管这一总体洞见在许多设置下都成立,但最优训练配置会随着隐私和数据预算而变化。理解准确的权衡至关重要,以确保在真实训练场景中审慎使用计算和隐私预算。上述可视化还显示,训练配置往往存在一定的回旋空间——也就是说,如果搭配正确的迭代次数和/或批量大小,一系列不同的模型规模可能会提供非常相似的效用。
应用缩放定律来构建 VaultGemma
Gemma 模型在设计时将责任与安全置于核心位置。这使它们自然成为开发像 VaultGemma 这样生产级、经 DP 训练模型的基础。
算法进展:大规模训练
我们在上文推导出的缩放定律,是朝着使用 DP 训练出有用的 Gemma 模型迈出的重要第一步。我们利用这些缩放定律来确定:在使用 DP 训练一个基于 Gemma 2、参数规模为 1B 且计算最优的模型时,需要多少计算量;以及如何在批量大小、迭代次数和序列长度之间分配这些计算量,以实现最佳效用。
支撑这些缩放定律的研究与 VaultGemma 的实际训练之间,一个显著差距在于我们对 Poisson sampling 的处理,而 Poisson sampling 是 DP-SGD 的核心组成部分。我们最初采用一种直接的方法,将数据按均匀批次加载;但随后改用 Poisson sampling,以在噪声量最小的情况下获得最佳隐私保证。这种方法带来了两个主要挑战:它会生成大小不同的批次,并且需要以特定的随机顺序处理数据。我们通过采用我们近期关于 Scalable DP-SGD 的工作解决了这一问题,该方法使我们能够以固定大小的批次处理数据——可以通过添加额外填充或进行裁剪来实现——同时仍保持强隐私保护。
结果
凭借我们新的缩放定律和先进的训练算法,我们构建了 VaultGemma,这是迄今为止最大的(10 亿参数)完全采用差分隐私预训练的开放模型,其方法能够产生高实用性的模型。
通过训练 VaultGemma,我们发现我们的缩放定律具有很高的准确性。VaultGemma 的最终训练损失与我们的方程预测结果非常接近,验证了我们的研究,并为社区未来开发私有模型提供了可靠路线图。

VaultGemma 1B(差分隐私)与其非私有对应模型(Gemma3 1B)以及较早基线模型(GPT-2 1.5B)的性能比较。结果量化了当前为实现隐私所需的资源投入,并表明现代 DP 训练产生的实用性可与大约五年前的非私有模型相媲美。
我们还在一系列标准学术基准(即 HellaSwag、BoolQ、PIQA、SocialIQA、TriviaQA、ARC-C、ARC-E)上,将我们模型的下游性能与其非私有对应模型进行比较。为了更好地理解这一性能,并量化当前为实现隐私所需的资源投入,我们还加入了与一个较早的、规模相近的 GPT-2 模型的比较,该模型在这些基准上的表现相近。这一比较表明,当今的私有训练方法所产生模型的效用与大约 5 年前的非私有模型相当,凸显出我们的工作将帮助社区系统性缩小的重要差距。
最后,该模型具备强大的理论和实证隐私保护。
形式化隐私保证
一般而言,在进行 DP 训练时,隐私参数(ε, δ)和隐私单元都是重要考量,因为二者共同决定了训练后的模型能够学习到什么。VaultGemma 采用序列级 DP 保证进行训练,其参数为(ε ≤ 2.0,δ ≤ 1.1e-10),其中一个序列由从异构数据源中提取的 1024 个连续 token 组成。具体而言,我们使用了与训练 Gemma 2 模型相同的训练混合数据,其中包含若干长度不一的文档。在预处理过程中,长文档会被拆分并分词为多个序列,较短的文档则被打包到单个序列中。虽然序列级隐私单元是我们训练混合数据的自然选择,但在数据与用户之间存在清晰映射关系的情况下,用户级差分隐私会是更好的选择。
这在实践中意味着什么?非正式地说,由于我们在序列级别提供保护,如果与任何(可能是私有的)事实或推断相关的信息出现在单个序列中,那么 VaultGemma 本质上并不知道该事实:对任何查询的响应在统计上都将类似于一个从未在相关序列上训练过的模型所产生的结果。然而,如果许多训练序列包含与某一特定事实相关的信息,那么一般而言,VaultGemma 将能够提供该信息。
经验性记忆
为了补充我们的序列级 DP 保证,我们对训练后模型的经验性隐私属性进行了额外测试。为此,我们用训练文档中的 50 个 token 前缀提示模型,以观察它是否会生成相应的 50 个 token 后缀。VaultGemma 1B 未显示出对其训练数据的可检测记忆,并成功证明了 DP 训练的有效性。
结论
VaultGemma 代表着在构建既强大又在设计上注重隐私的 AI 之路上迈出了重要一步。通过开发并应用对 DP 缩放定律的全新且稳健的理解,我们成功训练并发布了迄今为止最大的开放式 DP 训练语言模型。
尽管 DP 训练模型与非 DP 训练模型之间仍存在效用差距,但我们相信,随着对 DP 训练机制设计开展更多研究,这一差距可以被系统性缩小。我们希望 VaultGemma 以及我们的配套研究能够赋能社区,为每个人构建下一代安全、负责任且注重隐私的 AI。
致谢
我们要感谢整个 Gemma 和 Google Privacy 团队在本项目期间的贡献与支持,特别感谢 Peter Kairouz、Brendan McMahan 和 Dan Ramage 对博客文章提供反馈,Mark Simborg 和 Kimberly Schwede 在可视化方面提供帮助,以及 Google 内部在算法设计、基础设施实现和生产维护方面提供帮助的各个团队。以下人员直接参与了此处介绍的工作(按字母顺序排列):Borja Balle、Zachary Charles、Christopher A. Choquette-Choo、Lynn Chua、Prem Eruvbetine、Badih Ghazi、Steve He、Yangsibo Huang、Armand Joulin、George Kaissis、Pritish Kamath、Ravi Kumar、Daogao Liu、Ruibo Liu、Pasin Manurangsi、Thomas Mesnard、Andreas Terzis、Tris Warkentin、Da Yu 和 Chiyuan Zhang。
-
标签:
- 生成式 AI
- 开源模型与数据集
- 负责任的 AI
- 安全、隐私与防滥用
快速链接
- 论文
- 正文:Hugging Face
- 正文:Kaggle
- 技术报告