中文内容
已翻译official company source英文原文2025-10-25
今天,我们发布 Gemini 2.5 Flash-Lite 的稳定版,这是 Gemini 2.5 模型系列中速度最快、成本最低的模型(输入每 100 万 token 0.10 美元,输出每 100 万 token 0.40 美元)。我们打造 2.5 Flash-Lite,是为了推动单位成本智能水平的前沿;它具备原生推理能力,并可针对更高要求的用例选择性开启。继 2.5 Pro 和 2.5 Flash 的势头之后,这一模型完善了我们可用于规模化生产的 2.5 模型组合。
迄今为止我们最具成本效益、速度最快的 2.5 模型
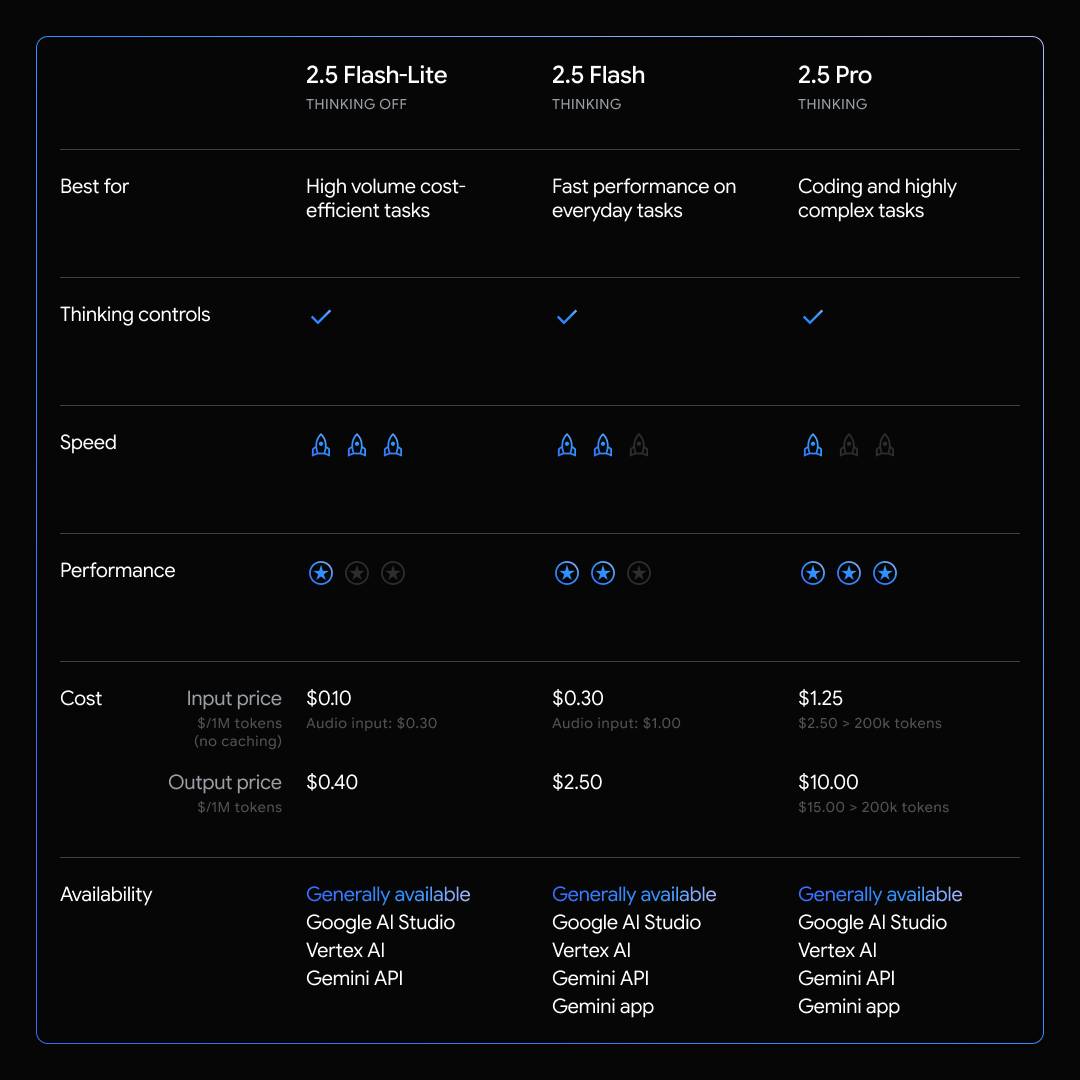
Gemini 2.5 Flash-Lite 在性能与成本之间取得平衡,同时不牺牲质量,尤其适用于翻译和分类等对延迟敏感的任务。
以下是它的突出之处:
- 同类最佳速度:在广泛的提示样本中,Gemini 2.5 Flash-Lite 的延迟低于 2.0 Flash-Lite 和 2.0 Flash。
- 成本效益:这是我们迄今成本最低的 2.5 模型,定价为输入 token 每 100 万 0.10 美元、输出 token 每 100 万 0.40 美元,使你能够以可负担的成本处理大量请求。与预览版发布时相比,我们还将音频输入价格降低了 40%。
- 智能且小巧:在编码、数学、科学、推理和多模态理解等广泛基准测试中,它整体质量高于 2.0 Flash-Lite。
- 功能完整:使用 2.5 Flash-Lite 构建时,你可以访问 100 万 token 的上下文窗口、可控的思考预算,并支持 Grounding with Google Search、Code Execution 和 URL Context 等原生工具。
Gemini 2.5 Flash-Lite 的实际应用
自 2.5 Flash-Lite 发布以来,我们已经看到一些非常成功的部署,以下是我们最喜欢的一些案例:
- Satlyt 正在构建一个去中心化空间计算平台,将改变卫星数据的处理和利用方式,用于在轨遥测的实时摘要、自主任务管理以及卫星间通信解析。与其基线模型相比,2.5 Flash-Lite 的速度使关键机载诊断延迟降低了 45%,功耗降低了 30%。
- HeyGen 使用 AI 为视频内容创建虚拟形象,并利用 Gemini 2.5 Flash-Lite 自动化视频规划、分析和优化内容,以及将视频翻译成 180 多种语言。这使他们能够为用户提供全球化、个性化的体验。
- DocsHound 使用 Gemini 2.5 Flash-Lite 处理长视频并以低延迟提取数千张截图,从而将产品演示转化为文档。这比传统方法更快地把素材转化为完整文档和 AI 智能体训练数据。
- Evertune 帮助品牌了解它们在各类 AI 模型中的呈现方式。Gemini 2.5 Flash-Lite 对他们而言具有变革意义,可显著加快分析和报告生成速度。其快速性能使他们能够迅速扫描并综合大量模型输出,为客户提供动态、及时的洞察。
你可以通过在代码中指定“gemini-2.5-flash-lite”开始使用 2.5 Flash-Lite。如果你正在使用预览版,可以切换到“gemini-2.5-flash-lite”,这是相同的底层模型。我们计划于 8 月 25 日移除 Flash-Lite 的预览别名。
准备开始构建了吗?现在可在 Google AI Studio 和 Vertex AI 中试用 Gemini 2.5 Flash-Lite 稳定版。
发布于:
- 正文:Gemini
- 正文:AI
- 公告
- 探索
- 正文:Gemini 2.5 Flash-Lite






