中文内容
首个 Gemma 模型于去年年初发布,此后已发展成为一个蓬勃发展的 Gemmaverse,累计下载量超过 1.6 亿次。这个生态系统包括我们面向从安全防护到医疗应用等各种场景的十余个专用模型系列,而最令人振奋的是来自社区的无数创新。从 Roboflow 等创新者构建企业级计算机视觉,到 Institute of Science Tokyo 创建高能力的日语 Gemma 变体,你们的工作为我们指明了前进方向。
在这一巨大势头的基础上,我们很高兴宣布 Gemma 3n 的完整发布。虽然上个月的预览版已让大家得以一窥其貌,但今天将解锁这一移动优先架构的全部能力。Gemma 3n 专为帮助塑造 Gemma 的开发者社区而设计。它受到你们喜爱的工具支持,包括 Hugging Face Transformers、llama.cpp、Google AI Edge、Ollama、MLX 以及许多其他工具,使你们能够轻松地针对特定的端侧应用进行微调和部署。本文是面向开发者的深度解析:我们将探讨 Gemma 3n 背后的一些创新,分享新的基准测试结果,并展示如何从今天开始构建。
Gemma 3n 有哪些新特性?
Gemma 3n 代表了端侧 AI 的一项重大进展,将强大的多模态能力带到边缘设备上,其性能达到了此前仅见于去年基于云的前沿模型的水平。
Youtube 视频链接(仅在禁用 JS 时可见)
- 多模态设计:Gemma 3n 原生支持图像、音频、视频和文本输入,以及文本输出。
- 针对端侧优化:Gemma 3n 模型以效率为重点进行设计,按有效参数规模提供两种大小:E2B 和 E4B。虽然它们的原始参数量分别为 5B 和 8B,但架构创新使其能够以与传统 2B 和 4B 模型相当的内存占用运行,最低仅需 2GB(E2B)和 3GB(E4B)内存。
- 突破性架构:Gemma 3n 的核心采用了多种创新组件,包括用于实现计算灵活性的 MatFormer 架构、用于提升内存效率的 Per Layer Embeddings(PLE)、用于提升架构效率的 LAuReL 和 AltUp,以及针对端侧用例优化的新型音频编码器和基于 MobileNet-v5 的视觉编码器。
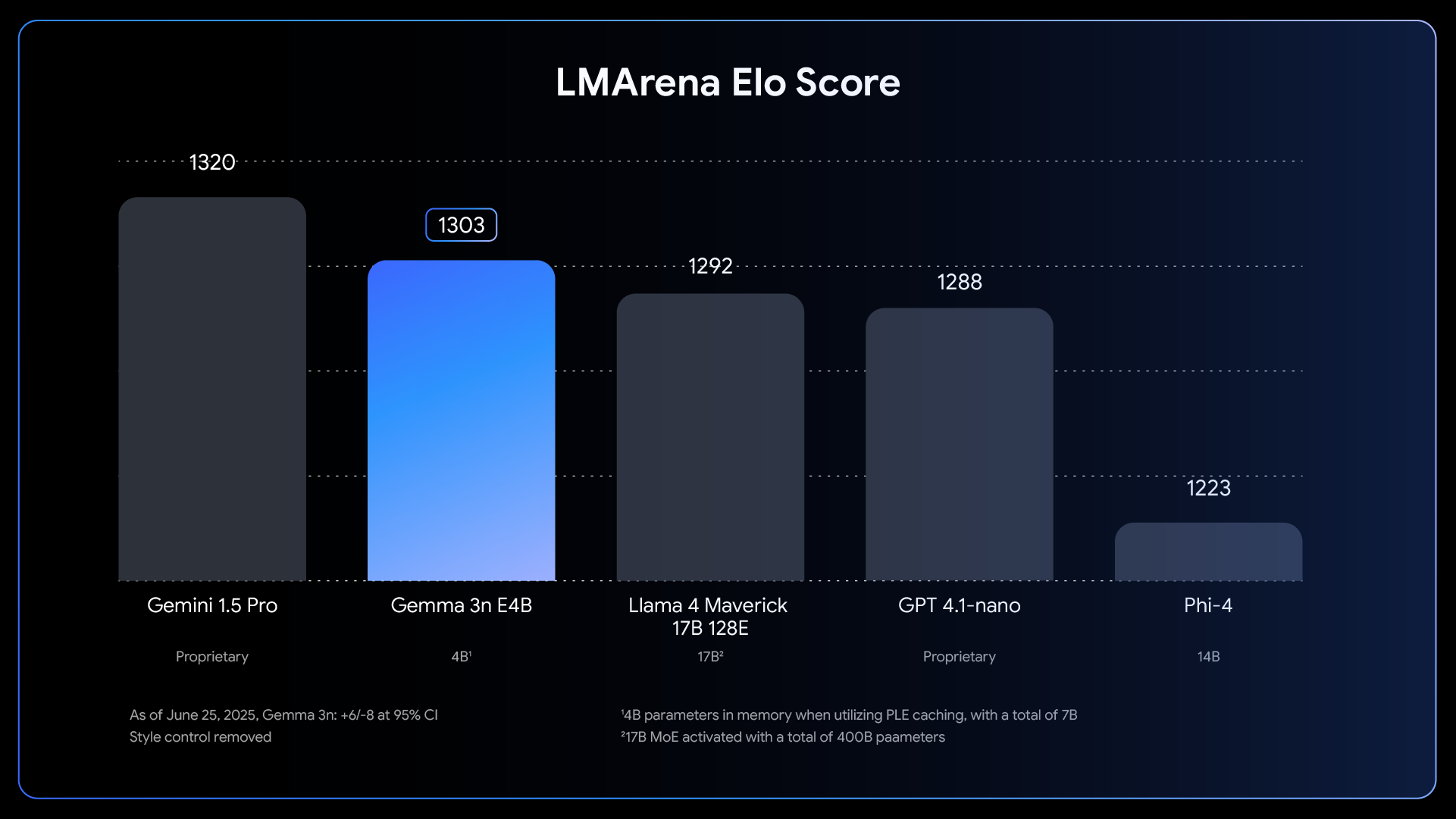
- 增强的质量:Gemma 3n 在多语言能力(支持 140 种语言的文本处理,以及 35 种语言的多模态理解)、数学、编码和推理方面实现了质量提升。E4B 版本的 LMArena 得分超过 1300,使其成为首个达到这一基准的 100 亿参数以下模型。
要实现端侧性能的这一跃升,需要从根本上重新思考模型。其基础是 Gemma 3n 独特的移动优先架构,而这一切都始于 MatFormer。
MatFormer:一个模型,多种规模
Gemma 3n 的核心是 MatFormer(🪆Matryoshka Transformer)架构,这是一种为弹性推理而构建的新型嵌套式 Transformer。可以把它想象成套娃:一个较大的模型包含了自身较小但功能完整的版本。这种方法将 Matryoshka Representation Learning 的概念从仅用于嵌入扩展到了所有 Transformer 组件。

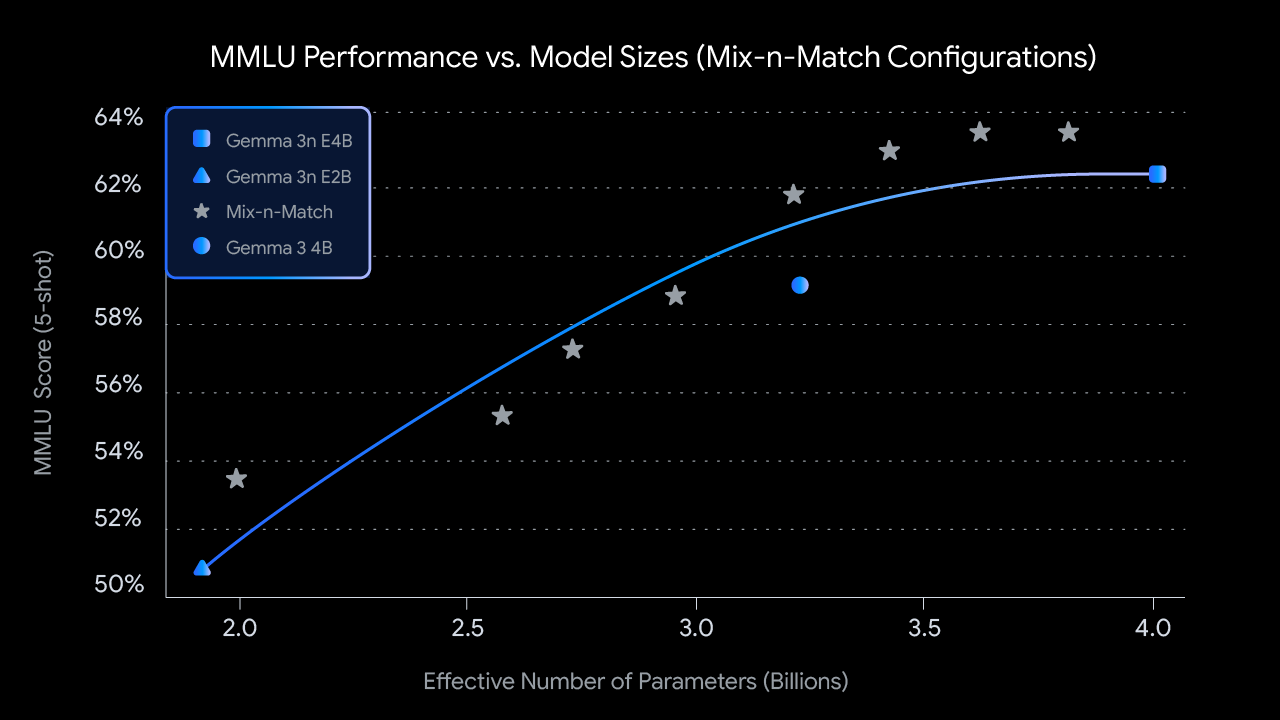
在对 4B 有效参数(E4B)模型进行 MatFormer 训练期间,一个 2B 有效参数(E2B)子模型会在其中同步优化,如上图所示。这为开发者在当前提供了两项强大的能力和用例:
1:预提取模型:你可以直接下载并使用主 E4B 模型以获得最高能力,或使用我们已为你提取好的独立 E2B 子模型,后者可提供最高 2 倍的推理速度。
2:使用 Mix-n-Match 自定义大小:为了实现针对特定硬件约束定制的更细粒度控制,你可以使用一种我们称为 Mix-n-Match 的方法,在 E2B 和 E4B 之间创建一系列自定义大小的模型。该技术允许你精确切分 E4B 模型的参数,主要方式是调整每层的前馈网络隐藏维度(从 8192 到 16384),并选择性地跳过某些层。我们正在发布 MatFormer Lab,这是一个展示如何检索这些最优模型的工具;这些模型是通过在 MMLU 等基准上评估各种设置确定的。
展望未来,MatFormer 架构也为弹性执行铺平了道路。虽然这项能力不属于今天发布的实现内容,但它允许单个已部署的 E4B 模型在运行时动态地在 E4B 和 E2B 推理路径之间切换,从而能够根据当前任务和设备负载实时优化性能和内存使用。
逐层嵌入(PLE):释放更高的内存效率
Gemma 3n 模型采用了逐层嵌入(Per-Layer Embeddings,PLE)。这项创新专为端侧部署而设计,因为它能在不增加设备加速器(GPU/TPU)所需高速内存占用的情况下,显著提升模型质量。
虽然 Gemma 3n E2B 和 E4B 模型的总参数量分别为 5B 和 8B,但 PLE 允许其中很大一部分参数(与每一层相关的嵌入)在 CPU 上高效加载和计算。这意味着只有核心 Transformer 权重(E2B 约为 2B,E4B 约为 4B)需要驻留在通常更受限的加速器内存(VRAM)中。

KV Cache 共享:更快的长上下文处理
处理长输入(例如源自音频和视频流的序列)对于许多先进的端侧多模态应用至关重要。Gemma 3n 引入了 KV Cache Sharing,这是一项旨在显著加快流式响应应用首个令牌生成时间的功能。
KV Cache Sharing 优化了模型处理初始输入阶段(通常称为“预填充”阶段)的方式。来自局部和全局注意力中间层的键和值会直接与所有顶层共享,相比 Gemma 3 4B,在预填充性能上实现了显著的 2 倍提升。这意味着模型能够比以往更快地摄取并理解较长的提示序列。
音频理解:引入语音转文本和翻译
Gemma 3n 使用基于 Universal Speech Model (USM) 的先进音频编码器。该编码器每 160 毫秒音频生成一个令牌(约每秒 6 个令牌),随后这些令牌会作为输入集成到语言模型中,从而提供对声音上下文的细粒度表示。
这一集成音频能力为端侧开发解锁了关键功能,包括:
- 自动语音识别(ASR):直接在设备上实现高质量的语音转文本转写。
- 自动语音翻译(AST):将口语翻译成另一种语言的文本。
我们观察到,在英语与西班牙语、法语、意大利语和葡萄牙语之间的翻译方面,AST 的效果尤为出色,这为面向这些语言应用的开发者提供了巨大潜力。对于语音翻译等任务,利用 Chain-of-Thought 提示可以显著提升结果。以下是一个示例:
<bos><start_of_turn>user
Transcribe the following speech segment in Spanish, then translate it into English:
<start_of_audio><end_of_turn>
<start_of_turn>model发布时,Gemma 3n 编码器被实现为可处理最长 30 秒的音频片段。然而,这并不是一个根本性限制。其底层音频编码器是流式编码器,经过额外的长格式音频训练后,能够处理任意长度的音频。后续实现将解锁低延迟、长时流式应用。
MobileNet-V5:新的最先进视觉编码器
除了集成的音频功能外,Gemma 3n 还配备了全新的高效视觉编码器 MobileNet-V5-300M,可在边缘设备上的多模态任务中提供最先进的性能。
MobileNet-V5 专为在受限硬件上实现灵活性和强大性能而设计,为开发者提供:
- 多种输入分辨率:原生支持 256x256、512x512 和 768x768 像素的分辨率,让你能够根据具体应用在性能与细节之间取得平衡。
- 广泛的视觉理解能力:通过在大规模多模态数据集上进行联合训练,它在各类图像和视频理解任务中表现出色。
- 高吞吐量:在 Google Pixel 上每秒最多可处理 60 帧,支持实时的端侧视频分析和交互式体验。
这一性能水平通过多项架构创新实现,包括:
- 基于 MobileNet-V4 模块(包括 Universal Inverted Bottlenecks 和 Mobile MQA)的先进基础架构。
- 显著扩展的架构,采用混合深度金字塔模型,其规模是最大 MobileNet-V4 变体的 10 倍。
- 一种新颖的多尺度融合 VLM 适配器,可提升 token 质量,从而获得更高的准确性和效率。
得益于新颖的架构设计和先进的蒸馏技术,MobileNet-V5-300M 显著优于 Gemma 3 中的基线 SoViT(使用 SigLip 训练,未进行蒸馏)。在 Google Pixel Edge TPU 上,它在量化情况下实现了 13 倍加速(未量化为 6.5 倍),参数量减少 46%,内存占用缩小 4 倍,同时在视觉语言任务上提供显著更高的准确性。
我们很高兴能分享更多关于该模型背后工作的内容。请关注我们即将发布的 MobileNet-V5 技术报告,其中将深入介绍模型架构、数据扩展策略和先进的蒸馏技术。
与社区共同构建
从第一天起就让 Gemma 3n 易于获取一直是我们的重点。我们很自豪能与众多出色的开源开发者合作,确保其在热门工具和平台上获得广泛支持,包括来自 AMD、Axolotl、Docker、Hugging Face、llama.cpp、LMStudio、MLX、NVIDIA、Ollama、RedHat、SGLang、Unsloth 和 vLLM 背后团队的贡献。
但这个生态系统只是开始。这项技术的真正力量在于你将用它构建什么。正因如此,我们推出 Gemma 3n Impact Challenge。你的任务:利用 Gemma 3n 独特的端侧、离线和多模态能力,构建一个让世界更美好的产品。我们设有 150,000 美元奖金,期待看到一个引人入胜的视频故事,以及一个展现现实世界影响力、令人惊叹的演示。加入挑战,助力建设更美好的未来。
立即开始使用 Gemma 3n
准备好立即探索 Gemma 3n 的潜力了吗?方法如下:
- 直接实验:只需点击几下,即可使用 Google AI Studio 试用 Gemma 3n。Gemma 模型也可以直接从 AI Studio 部署到 Cloud Run。
- 下载模型:在 Hugging Face 和 Kaggle 上查找模型权重。
- 学习与集成:深入阅读我们的全面文档,快速将 Gemma 集成到你的项目中,或从我们的推理和微调指南开始。
- 使用你喜爱的端侧 AI 工具进行构建:Google AI Edge Gallery/LiteRT-LLM、Ollama、MLX、llama.cpp、Docker、transformers.js 等。
- 使用你喜欢的开发工具:利用你偏好的工具和框架,包括 Hugging Face Transformers 和 TRL、NVIDIA NeMo Framework、Unsloth 以及 LMStudio。
- 按你的方式部署:Gemma 3n 提供多种部署选项,包括 Google GenAI API、Vertex AI、SGLang、vLLM 和 NVIDIA API Catalog。
- 正文:Gemma
- 人工智能
- 公告
- 移动应用开发
- 生成式人工智能
- 多模态 AI
- 学习
- 开发者工具
- 开放模型
- 正文:Gemma 3n
- 正文:Gemma
- 端侧 AI






