中文内容
正文:AWS News Blog
推出 S3 Files,使 S3 存储桶可作为文件系统访问
by Sébastien Stormacq 2026 年 4 月 7 日 in 正文:Amazon Simple Storage Service (S3), 公告, 发布, 新闻 Permalink Comments Share
我很高兴地宣布推出 Amazon S3 Files,这是一个新的文件系统,可将任何 AWS 计算资源与 Amazon Simple Storage Service (Amazon S3) 无缝连接。
十多年前,作为一名 AWS 培训师,我花了无数时间讲解对象存储和文件系统之间的根本差异。我最喜欢的类比是把 S3 对象比作图书馆里的书(你不能编辑某一页,必须替换整本书),而你计算机上的文件则可以逐页修改。我画图、创造比喻,并帮助客户理解为什么他们需要针对不同工作负载使用不同的存储类型。如今,这一区别变得稍微更灵活了。
借助 S3 Files,Amazon S3 成为首个也是唯一一个为你的数据提供功能完整、高性能文件系统访问的云对象存储。它使你的存储桶能够作为文件系统访问。这意味着,文件系统上的数据更改会自动反映到 S3 存储桶中,并且你可以对同步进行细粒度控制。S3 Files 可以附加到多个计算资源,从而在集群之间实现数据共享而无需复制。
直到现在,您必须在 Amazon S3 的成本、持久性以及能够原生使用其中数据的服务,或文件系统的交互能力之间做出选择。S3 Files 消除了这种权衡。S3 成为您组织所有数据的中心枢纽。无论您是在运行生产应用、训练 ML 模型,还是构建智能体 AI 系统,都可以从任何 AWS 计算实例、容器或函数直接访问它。
您可以在 Amazon Elastic Compute Cloud (Amazon EC2) 实例、运行在 Amazon Elastic Container Service (Amazon ECS) 或 Amazon Elastic Kubernetes Service (Amazon EKS) 上的容器,或 AWS Lambda 函数上,将任何通用型存储桶作为原生文件系统访问。该文件系统将 S3 对象呈现为文件和目录,支持所有 Network File System (NFS) v4.1+ 操作,例如创建、读取、更新和删除文件。
当你通过文件系统处理特定文件和目录时,相关的文件元数据和内容会被放置到该文件系统的高性能存储中。默认情况下,受益于低延迟访问的文件会从高性能存储中存储和提供。对于未存储在高性能存储中的文件,例如需要进行大型顺序读取的文件,S3 Files 会自动直接从 Amazon S3 提供这些文件,以最大化吞吐量。对于字节范围读取,只会传输请求的字节,从而最大限度减少数据移动和成本。
该系统还支持智能预取,以预判你的数据访问需求。你可以精细控制哪些内容被存储在文件系统的高性能存储中。你可以决定是加载完整文件数据还是仅加载元数据,这意味着你可以针对自己的特定访问模式进行优化。
在底层,S3 Files 使用 Amazon Elastic File System(Amazon EFS),并为活跃数据提供约 1 毫秒的延迟。该文件系统支持来自多个计算资源的并发访问,并具备 NFS close-to-open 一致性,因此非常适合会改变数据的交互式共享工作负载,从通过基于文件的工具协作的 agentic AI 智能体,到处理数据集的 ML 训练流水线。
让我来向你展示如何开始。创建我的第一个 Amazon S3 文件系统、挂载它,并从 EC2 实例中使用它非常简单。
我有一个 EC2 实例和一个通用型存储桶。在这个演示中,我配置一个 S3 文件系统,并使用常规文件系统命令从 EC2 实例访问该存储桶。
在这个演示中,我使用 AWS Management Console。你也可以使用 AWS Command Line Interface(AWS CLI)或基础设施即代码(IaC)。
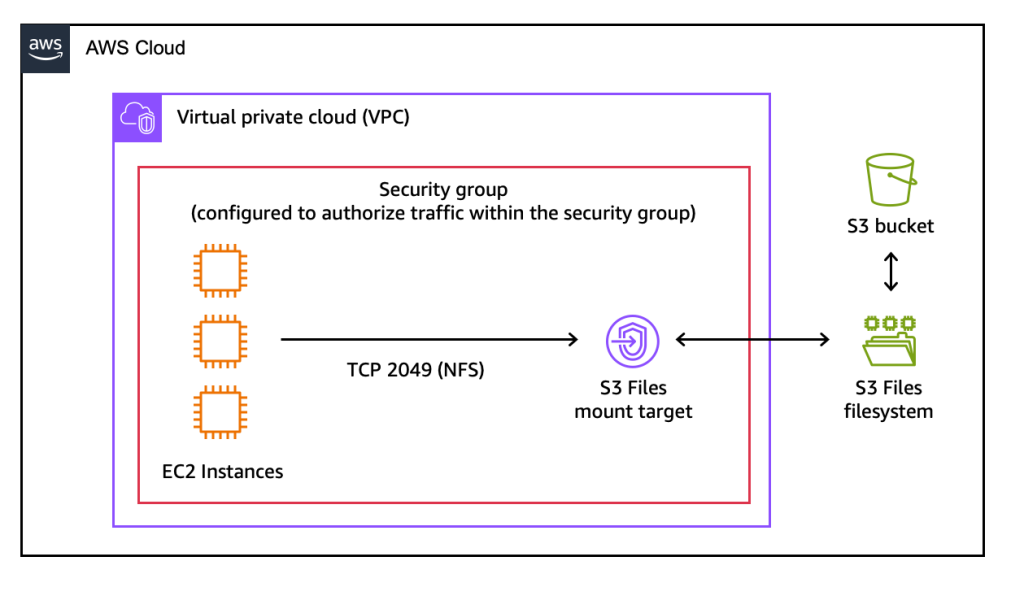
这是本演示的架构图。
步骤 1:创建一个 S3 文件系统。
在控制台的 Amazon S3 部分,我选择“文件系统”,然后选择“创建文件系统”。
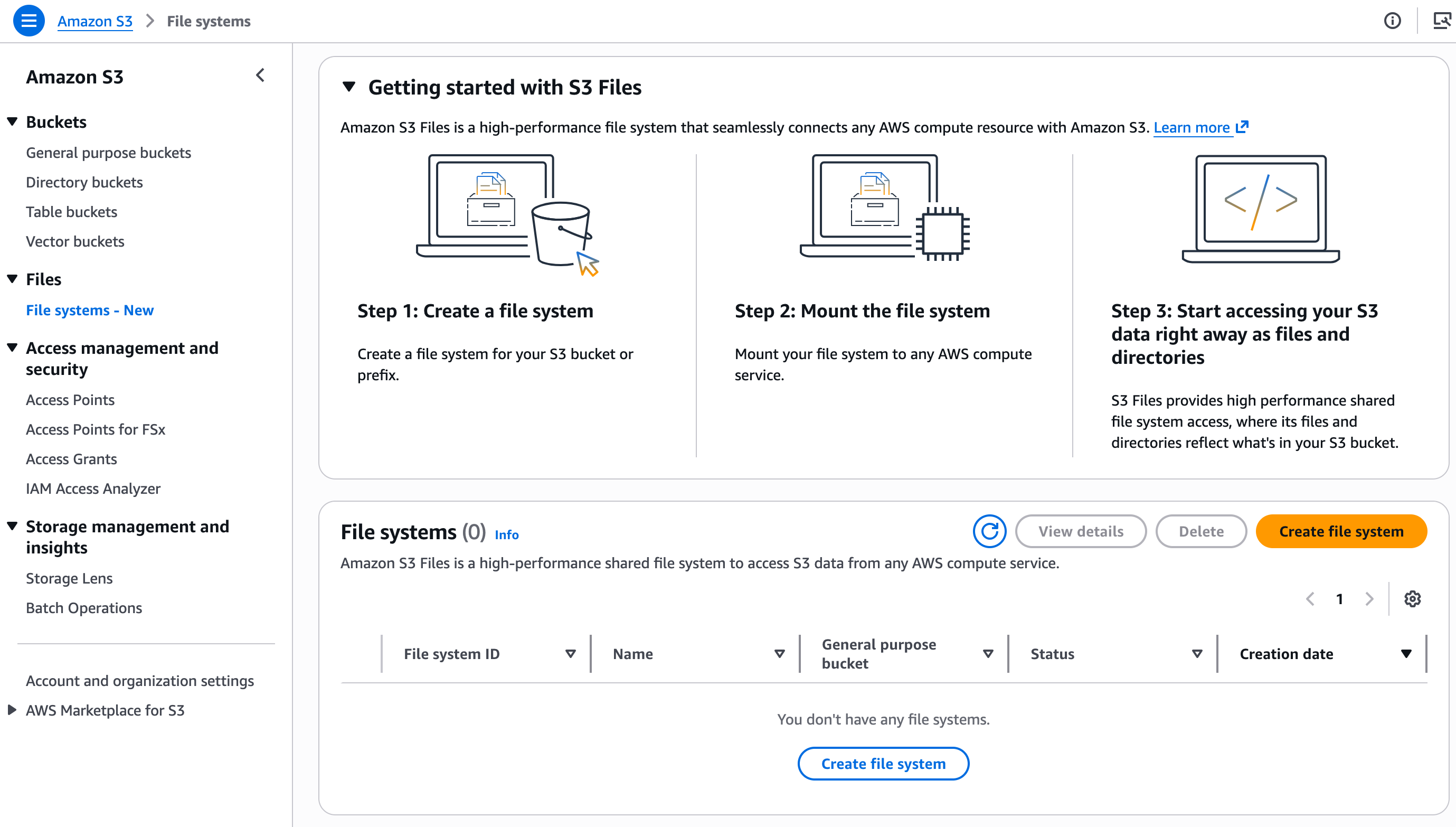
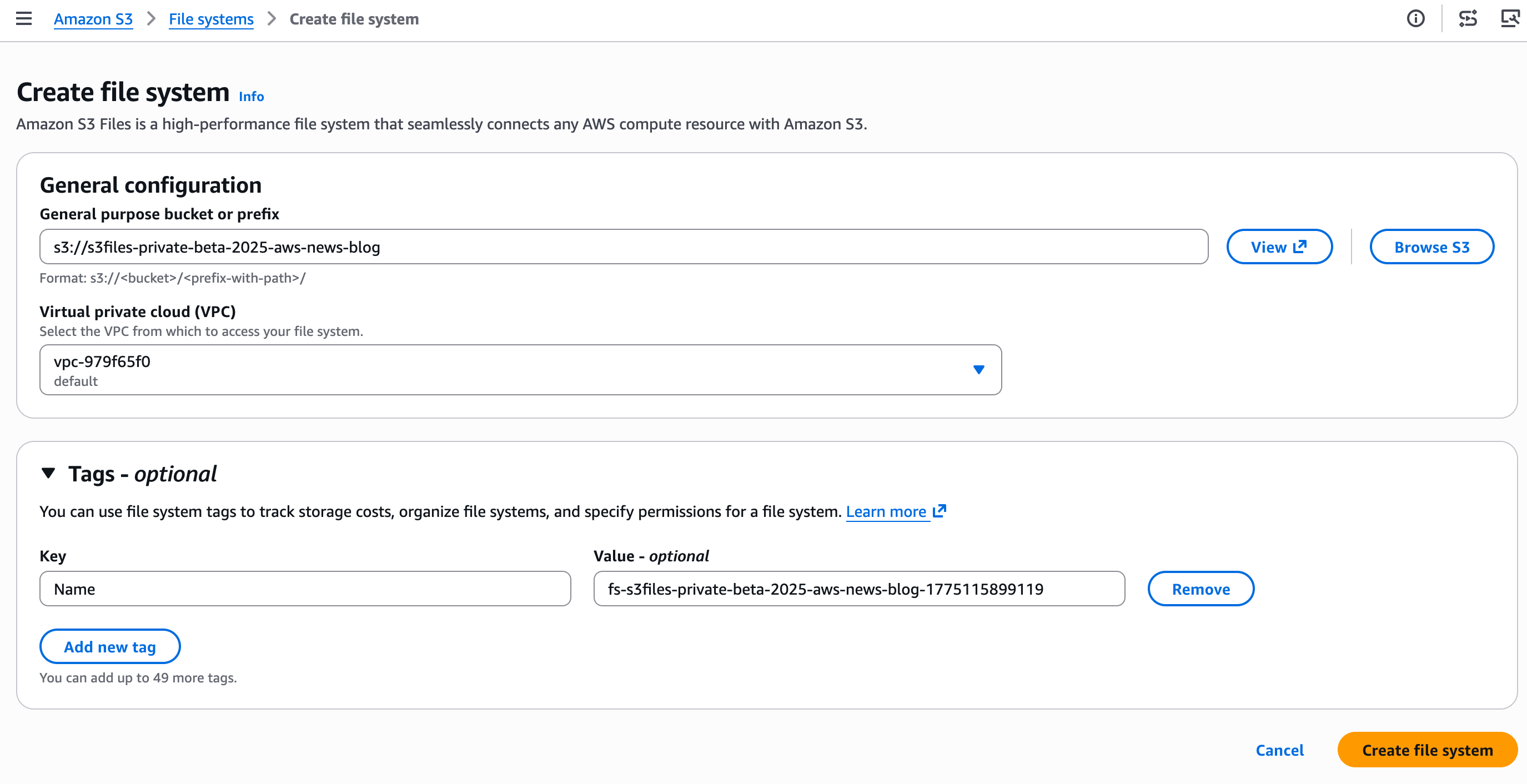
我输入要作为文件系统公开的存储桶名称,然后选择“创建文件系统”。
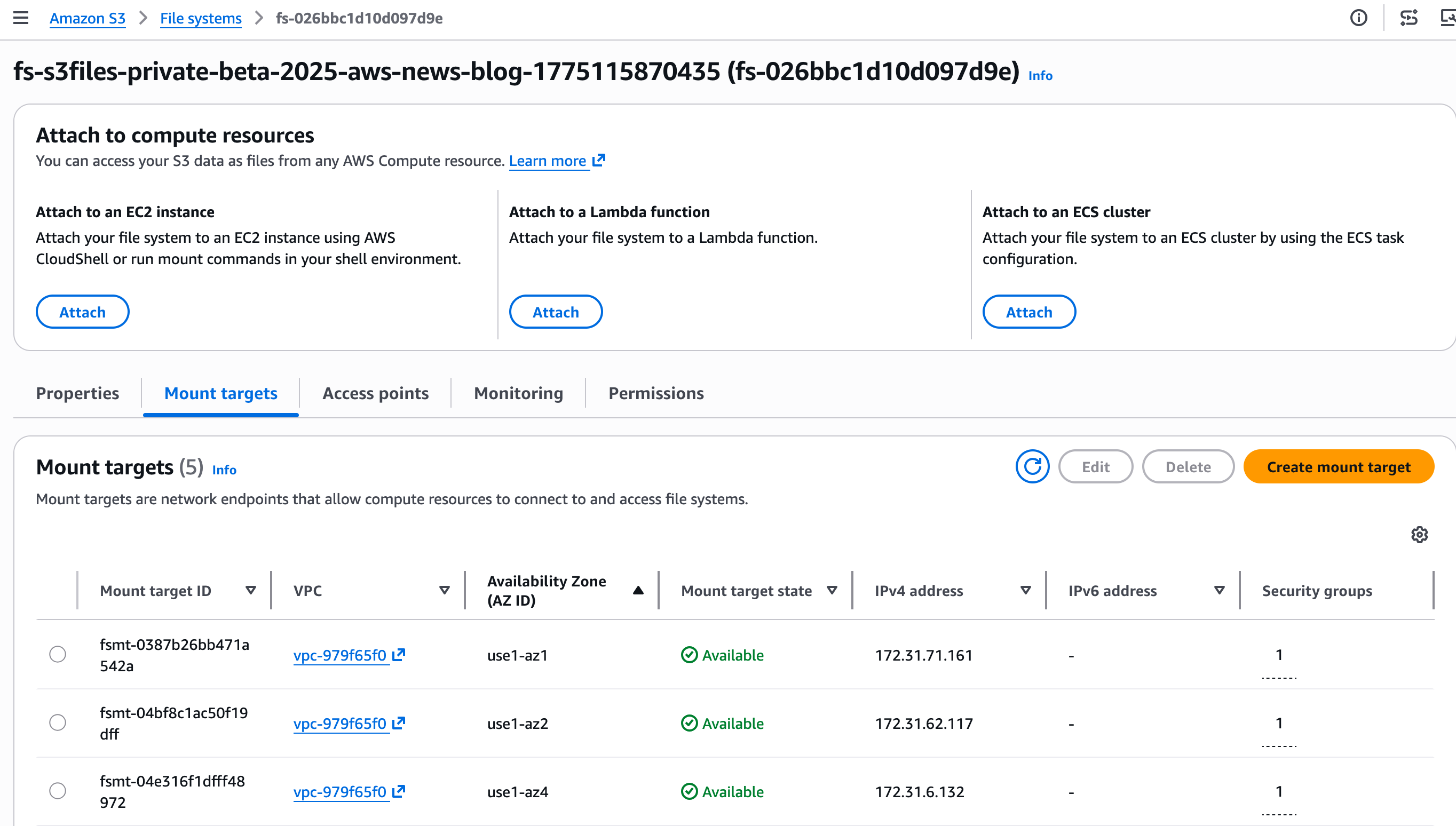
步骤 2:发现挂载目标。
挂载目标是一个网络端点,将位于我的虚拟私有云(VPC)中。它允许我的 EC2 实例访问 S3 文件系统。
控制台会自动创建挂载目标。我在 Mount targets 选项卡上记下 Mount target ID。
使用 CLI 时,需要用两个单独的命令来创建文件系统及其挂载目标。首先,我使用 create-file-system 创建 S3 文件系统。然后,我使用 create-mount-target 创建挂载目标。
步骤 3:在我的 EC2 实例上挂载文件系统。
连接到 EC2 实例后,我输入:
正文:sudo mkdir /home/ec2-user/s3files sudo mount -t s3files fs-0aa860d05df9afdfe:/ /home/ec2-user/s3files
现在,我可以通过挂载在 ~/s3files 的文件系统,使用标准文件操作直接处理我的 S3 数据。
当我在文件系统中更新文件时,S3 会自动管理所有更新,并在几分钟内将其作为新对象或现有对象的新版本导出回我的 S3 存储桶。
对 S3 存储桶中的对象所做的更改会在几秒钟内显示在文件系统中,但有时可能需要一分钟或更长时间。
# Create a file on the EC2 file system
echo "Hello S3 Files" > s3files/hello.txt
# and verify it's here
ls -al s3files/hello.txt
-rw-r--r--. 1 ec2-user ec2-user 15 Oct 22 13:03 s3files/hello.txt
# See? the file is also on S3
aws s3 ls s3://s3files-aws-news-blog/hello.txt
2025-10-22 13:04:04 15 hello.txt
# And the content is identical!
aws s3 cp s3://s3files-aws-news-blog/hello.txt . && cat hello.txt
Hello S3 Files须知事项 让我分享一些我认为你会觉得有用的重要技术细节。
- S3 Files 与 AWS Identity and Access Management (IAM) 集成,用于访问控制和加密。你可以使用身份策略和资源策略,在文件系统和对象级别管理权限。
- 数据在传输过程中始终使用 TLS 1.3 加密,在静态存储时使用 Amazon S3 托管密钥 (SSE-S3) 或通过 AWS Key Management Service (AWS KMS) 使用客户托管密钥进行加密。
- S3 Files 对文件和目录使用 POSIX 权限,根据 S3 存储桶中作为对象元数据存储的文件权限来检查用户 ID(UID)和组 ID(GID)。
- 使用 Amazon CloudWatch 指标监控 S3 Files 的驱动器性能和更新,并使用 AWS CloudTrail 记录管理事件。
- 请确认你的 EC2 实例上已安装最新版本的 EFS 驱动程序(amazon-efs-utils 软件包)。该软件包已预安装在 AWS 提供的 Amazon Machine Image(AMI)中。截至撰写本文时,你可以将其更新到最新版本。
- 在本文中,我向你展示了如何从 EC2 实例使用 S3 Files。你也可以从 ECS 或 EKS 容器(无论是否在 AWS Fargate 上)以及 Lambda 函数中,将你的 S3 存储桶挂载为文件系统。
我在与客户交流时经常听到的另一个问题,是如何为你的工作负载选择合适的文件服务。是的,我知道你在想什么:AWS 及其看似重叠的服务,让云架构师们在架构评审会议中一直有话可聊。让我来帮助揭开这个问题的神秘面纱。
当你需要通过高性能文件系统接口,以交互式、共享的方式访问存储在 Amazon S3 中的数据时,S3 Files 最为适合。它非常适用于多个计算资源——无论是生产应用程序、使用 Python 库和 CLI 工具的智能体 AI 代理,还是机器学习(ML)训练流水线——需要协同读取、写入和修改数据的工作负载。你可以在计算集群之间实现共享访问,而无需复制数据,并获得亚毫秒级延迟以及与你的 S3 存储桶的自动同步。
对于从本地 NAS 环境迁移的工作负载,Amazon FSx 提供你所需的熟悉功能和兼容性。Amazon FSx 也非常适合采用 Amazon FSx for Lustre 的高性能计算(HPC)和 GPU 集群存储。当你的应用程序需要 Amazon FSx for NetApp ONTAP、Amazon FSx for OpenZFS 或 Amazon FSx for Windows File Server 的特定文件系统能力时,它尤其有价值。
定价和可用性:S3 Files 现已在所有商业 AWS 区域提供。
您需要为存储在 S3 文件系统中的数据部分、对文件系统进行的小文件读取和所有写入操作,以及文件系统与 S3 存储桶之间数据同步期间的 S3 请求付费。Amazon S3 定价页面提供了所有详细信息。
根据与客户的讨论,我认为 S3 Files 通过消除数据孤岛、同步复杂性以及对象与文件之间的手动数据移动,有助于简化云架构。无论您是在运行已经适用于文件系统的生产工具,构建依赖基于文件的 Python 库和 shell 脚本的智能体 AI 系统,还是为 ML 训练准备数据集,S3 Files 都能让这些交互式、共享式、层级式工作负载直接访问 S3 数据,而无需在 Amazon S3 的持久性和成本优势与文件系统的交互能力之间做出取舍。现在,您可以将 Amazon S3 用作组织所有数据的存放位置,并且知道这些数据可从任何 AWS 计算实例、容器和函数直接访问。
要了解更多信息并开始使用,请访问 S3 Files 文档。
我很想了解您如何使用这项新功能。欢迎在下方评论中分享您的反馈。
— seb
正文:Sébastien Stormacq
Seb 自 20 世纪 80 年代中期第一次接触 Commodore 64 起就开始编写代码。他激励构建者释放 AWS 云的价值,凭借的是他由热情、激情、客户倡导、好奇心和创造力调配而成的独家秘诀。他的兴趣包括软件架构、开发者工具和移动计算。如果你想向他推销什么东西,请确保它有 API。可在 Bluesky、X、Mastodon 等平台关注 @sebsto。